

Mis à jours 1 septembre 2022 Comment surmonter les défis de la communication à distance, de l’asynchronicité et des transactions dans l’infrastructure de microservices ?
Les microservices font fureur. Ils ont une proposition de valeur intéressante, qui permet aux logiciels de commercialiser rapidement tout en développant avec de multiples équipes de développement logiciel. Ainsi, les microservices concernent la mise à l’échelle de votre force de développement tout en conservant une grande agilité et un rythme de développement rapide.

En un mot, vous décomposez un système en microservices. La décomposition n’est pas une nouveauté, mais avec les microservices, vous donnez aux équipes développant des services autant d’autonomie que possible.
Par exemple, une équipe dédiée possède le service et peut le déployer ou le redéployer quand il le souhaite. Ils font généralement aussi des devops pour pouvoir contrôler l’ensemble du service. Ils peuvent prendre des décisions technologiques plutôt autonomes et gérer leur propre infrastructure, par exemples les bases de données. Le fait d’être obligé de faire fonctionner le logiciel limite généralement le nombre de choix de technologie filaire, car les gens ont tendance à choisir la technologie ennuyeuse beaucoup plus souvent lorsqu’ils savent qu’ils devront l’utiliser plus tard.
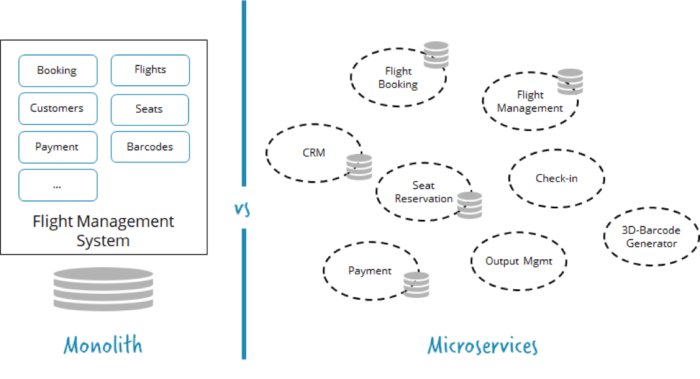
Les microservices concernent la décomposition, mais donnent à chaque composante un haut degré d’autonomie et d’isolement.
Un résultat fondamental de l’architecture des microservices est que chaque microservice est une application séparée communiquant à distance avec d’autres microservices. Cela rend les environnements microservices hautement distribués. Les systèmes distribués ont leurs propres défis. Dans cet article, nous allons vous guider à travers les pièges les plus courants de l’intégration des microservices.
1. La communication est complexe
La communication à distance doit inévitablement respecter les 8 erreurs de la programmation distribuée. Il n’est pas possible de cacher la complexité, et de nombreux efforts pour le faire (par exemple Corba ou RMI) ont échoué lamentablement. Une raison importante est que vous devez concevoir pour échouer dans vos services afin de réussir dans un environnement où l’échec est la nouvelle normale. Mais, il existe des modèles et des cadres communs qui peuvent vous aider à vous en sortir. Commençons par un exemple – une situation réelle que vous pouvez rencontrer assez régulièrement :
Je voulais prendre l’avion vers Londres. Quand j’ai reçu l’invitation à l’enregistrement, je suis allé sur le site Web de la compagnie aérienne, j’ai choisi mon siège et j’ai appuyé sur le bouton pour récupérer ma carte d’embarquement. Il m’a donné la réponse suivante :
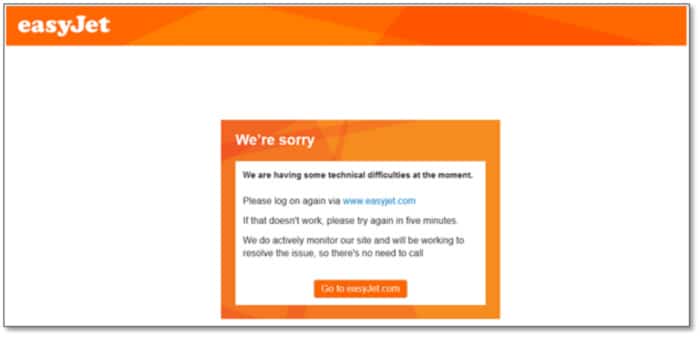
Supposons un instant que la compagnie aérienne utilise des microservices (ce qui pourrait ne pas être le cas, mais d’autres compagnies aériennes le font).
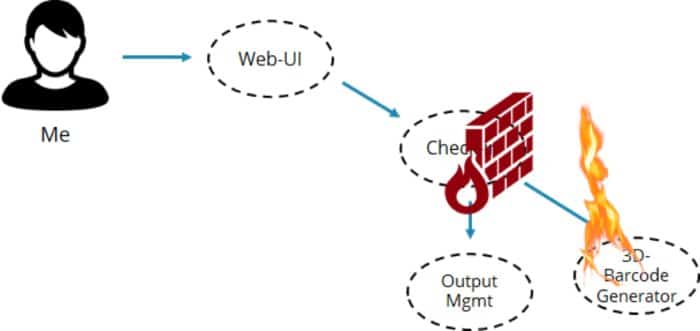
La première chose que j’ai remarquée : l’erreur est revenue assez rapidement, et d’autres parties du site se sont comportées normalement. Donc, ils ont utilisé le modèle important « fail fast ». Une erreur dans la génération du code à barres n’a pas affecté l’ensemble du site Web. En effet, je pourrais faire tout le reste ; mais je n’ai tout simplement pas pu obtenir la carte d’embarquement. « Fail fast » est bien, car il empêche les erreurs locales d’endommager le système entier. Les modèles bien connus dans ce domaine sont les disjoncteurs, les cloisons et les mailles de service. Ces modèles sont vitaux pour la survie des systèmes distribués.
Échouer rapidement n’est pas suffisant
Mais, échouer rapidement n’est pas suffisant. Il décharge la gestion des échecs aux clients. Dans ce cas, vous devez faire une nouvelle tentative. Dans la situation ci-dessus, il faut attendre le lendemain jusqu’à ce que les problèmes soient résolus pour obtenir la carte d’embarquement ! En effet, vous devriez utiliser vos propres outils pour persister dans la nouvelle tentative (le calendrier par exemple) et vous assurer de ne pas oublier de le faire le lendemain.
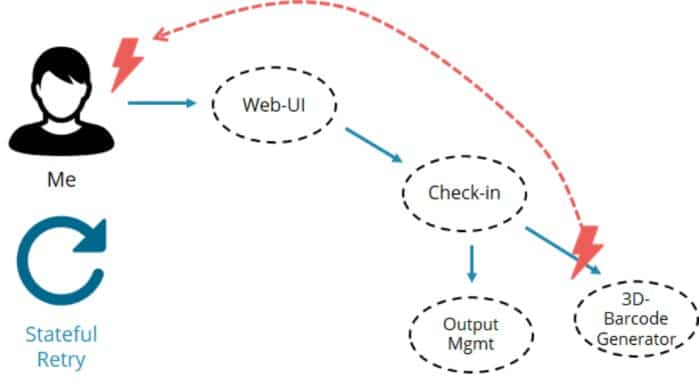
Pourquoi la compagnie aérienne ne fait-elle pas la même chose ? Ils connaissent les coordonnées de ses clients et peuvent leur envoyer la carte d’embarquement de manière asynchrone chaque fois qu’elle sera prête à être envoyée. La meilleure réponse aurait été :

Cela serait non seulement beaucoup plus pratique, mais réduirait également la complexité globale, car le nombre de composants qui ont besoin de voir l’échec est réduit :
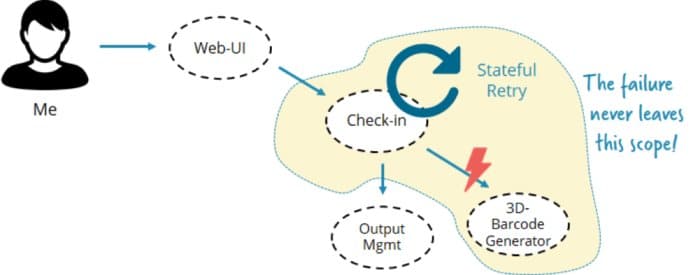
Vous pouvez adopter le même principe à la communication de service à service. Chaque fois qu’un service peut résoudre les échecs lui-même, il encapsule un comportement important. Cela rend la vie de tous les clients beaucoup plus facile et l’API beaucoup plus propre. La résolution des échecs peut concerner l’état (certains l’appellent longue exécution). On considère la gestion d’état comme une question clé pour la gestion des défaillances dans les microservices.
Bien sûr, le comportement décrit ci-dessus n’est pas toujours ce que vous voulez et la remise de l’échec au client peut être très bien. Mais, cela devrait être une décision consciente qui est faite en fonction des besoins de l’entreprise.
La plupart du temps, une autre raison fait que l’on évite les tentatives de réitération : cela concerne la complexité de la gestion de l’état. Le service doit être ressayé pendant des minutes, des heures ou des jours. Il doit le faire de manière fiable (rappelez-vous : je veux ma carte d’embarquement même s’il y a un redémarrage du système entre les deux), et cela implique la gestion de l’état persistant.
Comment gérer l’état persistant ?
Il y a deux manières typiques de gérer l’état persistant : Vous pouvez le stocker dans une base de données, ou vous pouvez utiliser un moteur de workflow léger ou une machine d’état.
La première méthode – stocker des entités dans une base de données – commence de manière très directe, mais elle entraîne généralement beaucoup de complexité accidentelle. Vous avez non seulement besoin de la table de base de données, mais aussi d’un composant du planificateur pour effectuer la nouvelle tentative. Vous avez probablement besoin d’un composant de surveillance pour voir ou modifier les tâches en attente. Et vous devez vous préoccuper de la gestion des versions si la logique métier globale change pendant que vous souhaitez effectuer la nouvelle tentative. Ainsi de suite.
Cette façon de penser conduit beaucoup de développeurs à ignorer une gestion correcte des défaillances comme décrit ci-dessus, conduisant à une complexité accrue de l’ensemble de l’architecture – et une mauvaise expérience client.
Au lieu de cela, il faut tirer parti des moteurs de workflow légers ou des machines d’état. Ces moteurs sont construits pour conserver l’état persistant et gérer les besoins ultérieurs autour du langage de flux, de la surveillance et des opérations, de la mise à l’échelle pour gérer des volumes élevés, etc.
Il y a quelques moteurs légers sur le marché. Beaucoup d’entre eux utilisent la norme ISO BPMN pour définir les flux et sont open source. Là, on va utiliser le moteur de workflow open source de Camunda pour illustrer le principe de base. Pour le cas d’utilisation simple esquissé ci-dessus, un workflow peut être facilement créé en utilisant un Java DSL :
Bpmn.createExecutableProcess(“generateBoardingPass”) .startEvent() .serviceTask().camundaClass(Generate3dBarcodeAdapter.class) .camundaAsyncBefore().camundaFailedJobRetryTimeCycle(“R30/PT15M”) .serviceTask().camundaClass(SendBoardingPass.class) .camundaAsyncBefore().camundaFailedJobRetryTimeCycle(“R5/PT1M”) .endEvent();
Une autre option consiste à modéliser graphiquement le workflow dans BPMN :
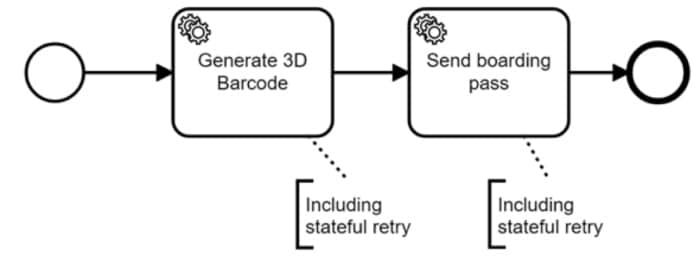
Ces moteurs de workflow sont très flexibles en termes d’architecture. De nombreux développeurs pensent qu’un moteur de workflow est un composant centralisé, mais ce n’est pas le cas. Il n’est pas nécessaire d’introduire un composant centralisé ! Si différents services nécessitent un moteur de workflow, chaque service peut exécuter son propre moteur pour maintenir l’autonomie et l’isolement des services. Ceci est discuté plus en détail dans ce billet sur les options d’architecture.
Une autre idée fausse est que les workflows forcent les développeurs à passer au traitement asynchrone. Ce n’est pas vrai non plus. Dans l’exemple ci-dessus, le composant check-in peut renvoyer la carte d’embarquement de manière synchrone lorsque tout se passe bien. Ce n’est qu’en cas d’erreur que vous retournerez au traitement asynchrone. Cela peut facilement se traduire par le code de retour HTTP, 200 signifie “Tout est OK, voici votre résultat” et 202 signifie “Je l’ai, je vous rappelle.” Il y a un exemple concret de code pour gérer cela, qui tire parti d’un simple sémaphore.
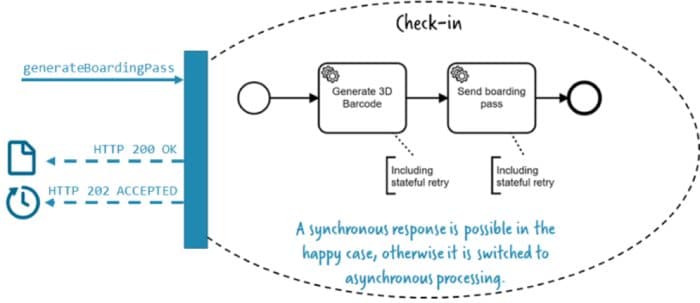
Un moteur de workflow comme une partie vitale de la boîte à outils pour la gestion correcte des échecs, ce qui implique souvent un comportement de longue durée, comme une nouvelle tentative d’état.
2. L’asynchronisme nécessite une attention
Cela nous conduit à une communication asynchrone, qui signifie le plus souvent la messagerie. L’asynchronisme est souvent préconisé comme le meilleur défaut dans les systèmes distribués car il assure le découplage, en particulier le découplage temporel, car tout message peut être envoyé indépendamment de la disponibilité du récepteur. Le message sera livré dès que le fournisseur de service est disponible sans magie supplémentaire.
Ainsi, le problème de réessayer est obsolète, mais un problème comparable se pose : vous devez vous soucier des délais d’attente. Supposons que la compagnie aérienne utilise la communication asynchrone dans le scénario d’enregistrement. Le composant d’enregistrement envoie un message au service de génération de codes à barres, puis attend la réponse. Vous n’avez pas à vous préoccuper de la disponibilité du générateur de codes à barres, car le bus de messages transmettra le message chaque fois que nécessaire.
Mais que faire si la demande ou la réponse est perdue pour une raison quelconque ? Vous coincez-vous dans l’enregistrement pour toujours, sans envoyer la carte d’embarquement au client sans le remarquer ? Beaucoup d’entreprises le font, ce qui nous mène à nouveau en tant que client, de surveiller la réponse et prendre des mesures si aucune carte d’embarquement n’arrive dans un délai imparti.
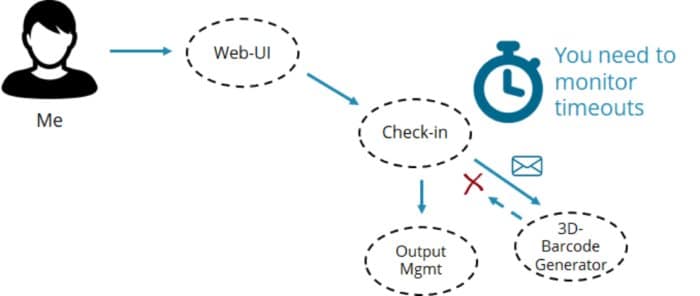
La meilleure approche consiste à faire en sorte que le service surveille lui-même le délai d’expiration et exécute un repli chaque fois que le code à barres n’arrive pas à temps. Une solution de repli possible consiste à renvoyer le message, à le réessayer essentiellement à nouveau.
Vous pouvez également tirer parti de la technologie d’automatisation du workflow pour ce cas d’utilisation. Un workflow dans BPMN peut ressembler à ceci :
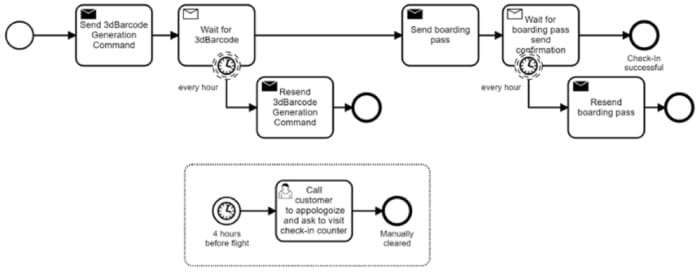
En prime, vous obtenez des rapports gratuits sur le nombre de tentatives, les temps de réponse et le nombre de workflows qui n’ont pas pu être traités à temps. Les opérateurs peuvent facilement inspecter et réparer les instances de workflow ayant échoué en disposant beaucoup de contexte disponible, par exemple : les données qui ont été incluses dans un message et quand exactement le message a été envoyé. Ce niveau de visibilité et de contrôle opérationnel est généralement manqué dans les solutions basées sur des messages purs.
Il y a même des entreprises qui vont plus loin et utilisent un moteur de workflow au lieu d’utiliser des logiciels de messagerie pour répartir le travail entre les microservices. Ceci est possible si le moteur de workflow n’appelle pas activement un service ou n’envoie pas de message (appelé principe de push) mais s’appuient sur les travailleurs pour demander le travail (appelé principe de pull). Maintenant, la file d’attente de travail dans le moteur de workflow se comporte comme une file d’attente de messages. Si on leur demande pourquoi ils préféraient un moteur de workflow, ils disent que les solutions de messagerie n’avaient pas la même qualité de visibilité et d’outillage, et qu’ils voudraient éviter de construire leur propre outil d’exploitation.
3. Les transactions distribuées sont difficiles
Une transaction est une série d’opérations effectuées de manière tout ou rien. Nous le savons tous à partir de bases de données. Vous commencez une transaction, effectuez plusieurs opérations, puis validez ou annulez la transaction. Ces transactions sont appelées ACID : atomique, cohérent, isolé et durable.
Dans les systèmes distribués, vous ne pouvez pas compter sur les transactions ACID. Oui, il existe des protocoles comme XA qui implémentent une validation dite en deux phases, ou WS-AtomicTransaction ou des implémentations sophistiquées comme Google Spanner. Mais, le consensus actuel est que ces protocoles sont trop chers, ou trop compliqués, ou simplement ne peuvent pas évoluer. « Life Beyond Distributed Transactions : An Apostate’s Opinion. » de Pat Helland est un bon historique.
Mais bien sûr, l’exigence de transactions commerciales ne disparaît pas. Le truc commun pour résoudre les transactions commerciales sans ACID est d’utiliser la compensation. Cela signifie que vous exécutez des opérations d’annulation pour toutes les activités incorrectement exécutées dans le passé. BPMN dispose de cette fonctionnalité intégrée, vous pouvez donc définir ces activités d’annulation et un moteur de workflow prend soin de les exécuter de manière fiable dans le bon ordre. Cette fois, prenons l’exemple de réservation de billets :
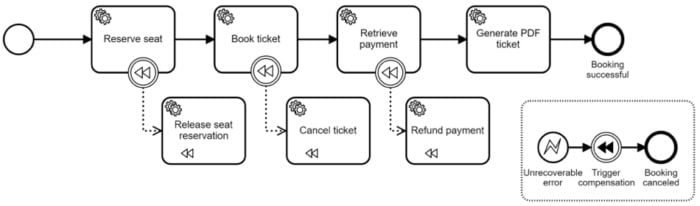
Ceci est souvent aussi connu comme le modèle Saga, qui est devenu très populaire récemment.
Notez que cette approche est différente des transactions ACID, car vous pouvez avoir des états intermédiaires peu cohérents. Donc, je pourrais avoir une place réservée, mais pas encore un billet valide réservé. Ou je pourrais avoir un billet sans l’avoir payé pour le moment. La vérité est qu’il est souvent acceptable de vivre avec ces incohérences temporaires, tant que vous vous assurez de les nettoyer et de remettre le système dans un état cohérent. C’est ce qu’on appelle la cohérence éventuelle, qui est un concept important dans les systèmes distribués. “Adopter une cohérence éventuelle dans le réseau SoA“, c’est plutôt bien :
La cohérence éventuelle génère généralement de meilleures performances, une opération plus simple et une meilleure évolutivité, tout en obligeant les programmeurs à comprendre un modèle de données plus complexe.
La bonne nouvelle est que l’automatisation du workflow facilite le traitement de la rémunération. C’est parce que le moteur de workflow peut prendre soin d’invoquer toutes les activités de compensation nécessaires de manière fiable.




