
Mis à jours 5 septembre 2022 Rapide, flexible et offrant de nombreux avantages pour les développeurs, Apache Spark est la plate-forme leader pour le SQL à grande échelle, le traitement par lots, le traitement de flux et l’apprentissage automatique.
Depuis ses humbles débuts dans l’AMPLab à U.C. Berkeley en 2009, Apache Spark est devenu l’un des principaux frameworks de traitement de Big Data distribué dans le monde. Spark peut être déployé de différentes manières, fournit des liaisons natives pour les langages de programmation Java, Scala, Python et R, et prend en charge SQL, les données en continu, l’apprentissage automatique et le traitement graphique. Vous constaterez qu’il est utilisé par les banques, les sociétés de télécommunications, les sociétés de jeux, les gouvernements et tous les grands géants de la technologie comme Apple, Facebook, IBM et Microsoft.

Dès sa sortie, Spark peut s’exécuter en mode de cluster autonome nécessitant simplement le framework Apache Spark et une machine virtuelle Java sur chaque machine de votre cluster. Cependant, il est plus probable que vous souhaitiez tirer parti d’un système de gestion de ressources ou de clusters pour prendre soin d’affecter des travailleurs à la demande pour vous. Dans l’entreprise, cela s’exécutera normalement sur Hadoop YARN (c’est ainsi que les distributions Cloudera et Hortonworks exécutent des jobs Spark), mais Apache Spark peut également fonctionner sur Apache Mesos, tandis que le travail progresse sur l’ajout de support natif pour Kubernetes.
Si vous recherchez une solution gérée, Apache Spark peut être intégré à Amazon EMR, à Google Cloud Dataproc et à Microsoft Azure HDInsight. Databricks, la société qui emploie les fondateurs d’Apache Spark, propose également la plate-forme Databricks Unified Analytics, un service géré complet qui offre des clusters Apache Spark, un support de streaming, un développement Web intégré et des performances d’E/S cloud optimisées sur une distribution standard d’Apache Spark.
Spark vs. Hadoop

Il convient de souligner qu’Apache Spark vs Apache Hadoop est un peu un abus de langage. Vous trouverez Spark inclus dans la plupart des distributions Hadoop ces jours-ci. Mais en raison de deux grands avantages, Spark est devenu le cadre de choix lors du traitement des mégadonnées, dépassant l’ancien paradigme MapReduce qui a permis à Hadoop de prendre de l’importance.
Le premier avantage est la vitesse. Le moteur de données en mémoire de Spark signifie qu’il peut effectuer des tâches jusqu’à cent fois plus vite que MapReduce dans certaines situations, en particulier lorsqu’il est comparé à des tâches en plusieurs étapes qui nécessitent l’écriture d’un état sur le disque entre les étapes. Même les travaux Apache Spark où les données ne peuvent pas être complètement contenues dans la mémoire ont tendance à être environ 10 fois plus rapide que leur homologue MapReduce.
Le deuxième avantage est : l’API Spark offre de nombreux avantages pour les développeurs. Aussi important que soit l’accélération de Spark, on pourrait dire que la convivialité de l’API Spark est encore plus importante.
Spark Core
En comparaison avec MapReduce et d’autres composants Apache Hadoop, l’API Apache Spark offre de nombreux avantages pour les développeurs, cachant une grande partie de la complexité d’un moteur de traitement distribué derrière de simples appels de méthode. L’exemple canonique de ceci est comment presque 50 lignes de code de MapReduce pour compter des mots dans un document peuvent être réduites à juste quelques lignes d’Apache Spark (ici montré dans Scala) :
val textFile = sparkSession.sparkContext.textFile(“hdfs:///tmp/words”) val counts = textFile.flatMap(line => line.split(“ “)) .map(word => (word, 1)) .reduceByKey(_ + _) counts.saveAsTextFile(“hdfs:///tmp/words_agg”)
En fournissant des liaisons à des langages populaires pour l’analyse de données comme Python et R, ainsi que Java et Scala, Apache Spark permet à tout le monde, depuis les développeurs d’applications aux data scientists, d’exploiter son évolutivité et sa vitesse de manière accessible.
Spark RDD
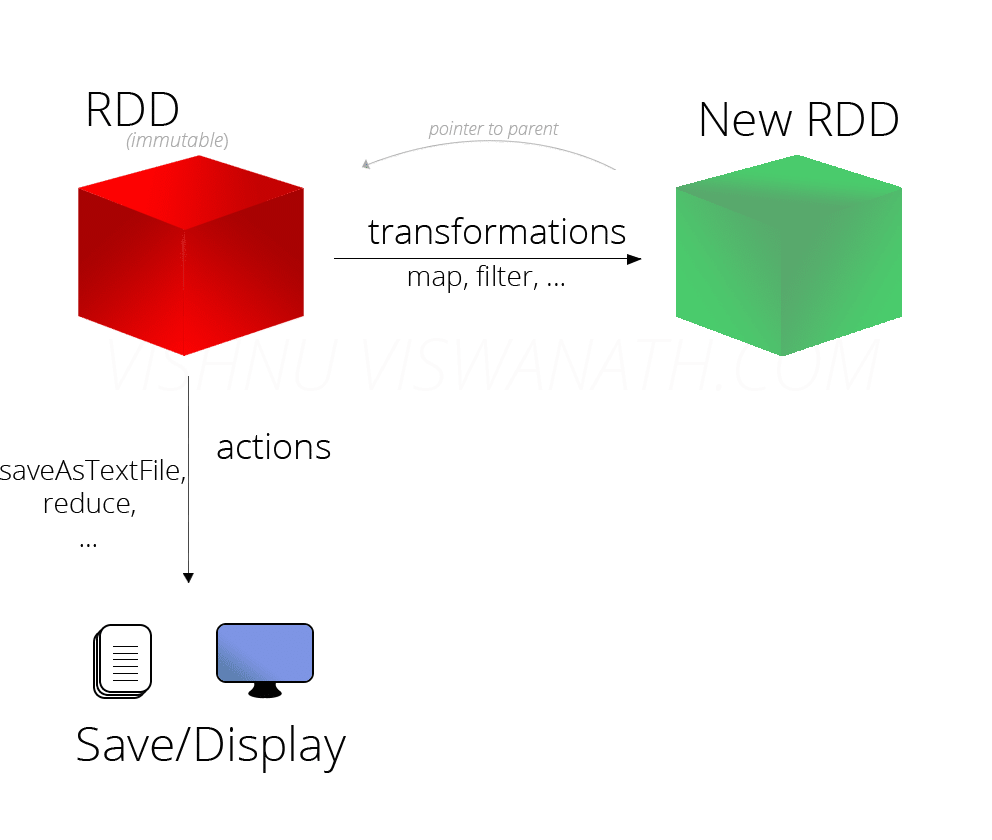
Au cœur d’Apache Spark se trouve le concept de RDD (Resilient Distributed Dataset), une abstraction de programmation qui représente une collection immuable d’objets pouvant être répartis sur un cluster informatique. Les opérations sur les RDD peuvent également être réparties sur le cluster et exécutées dans un processus de traitement par lots parallèle, ce qui permet un traitement parallèle rapide et évolutif.
Les RDD peuvent être créés à partir de fichiers texte simples, de bases de données SQL, de bases de données NoSQL (telles que Cassandra et MongoDB), de compartiments Amazon S3 et bien plus encore. Une grande partie de l’API Spark Core repose sur ce concept de RDD, permettant la création de cartes traditionnelles et la réduction des fonctionnalités, mais également la prise en charge intégrée de la jonction des ensembles de données, du filtrage, de l’échantillonnage et de l’agrégation.
Spark fonctionne de manière distribuée en combinant un processus de noyau de pilote qui divise une application Spark en tâches et les distribue parmi de nombreux processus d’exécution qui effectuent le travail. Ces exécuteurs peuvent être mis à l’échelle selon les besoins de l’application.
Spark SQL
Originalement connu sous le nom de Shark, Spark SQL est devenu de plus en plus important pour le projet Apache Spark. C’est probablement l’interface la plus couramment utilisée par les développeurs d’aujourd’hui lors de la création d’applications. Spark SQL se concentre sur le traitement de données structurées, en utilisant une approche de données empruntée à R et Python (dans Pandas). Mais comme son nom l’indique, Spark SQL fournit également une interface compatible avec SQL2003 pour la requête de données, apportant la puissance d’Apache Spark aux analystes ainsi qu’aux développeurs.
Outre la prise en charge SQL standard, Spark SQL fournit une interface standard pour la lecture et l’écriture dans d’autres banques de données, notamment JSON, HDFS, Apache Hive, JDBC, Apache ORC et Apache Parquet, elles sont toutes prises en charge dès la première utilisation. D’autres stockages populaires – Apache Cassandra, MongoDB, Apache HBase et bien d’autres – peuvent être utilisés en tirant parti des connecteurs séparés depuis l’écosystème Spark Packages.
Sélectionner certaines colonnes à partir d’une base de données est aussi simple que cette ligne :
citiesDF.select(“name”, “pop”)
À partir de l’interface SQL, nous enregistrons la trame données sous la forme d’une table temporaire, après quoi nous pouvons émettre des requêtes SQL à son encontre :
citiesDF.createOrReplaceTempView(“cities”) spark.sql(“SELECT name, pop FROM cities”)
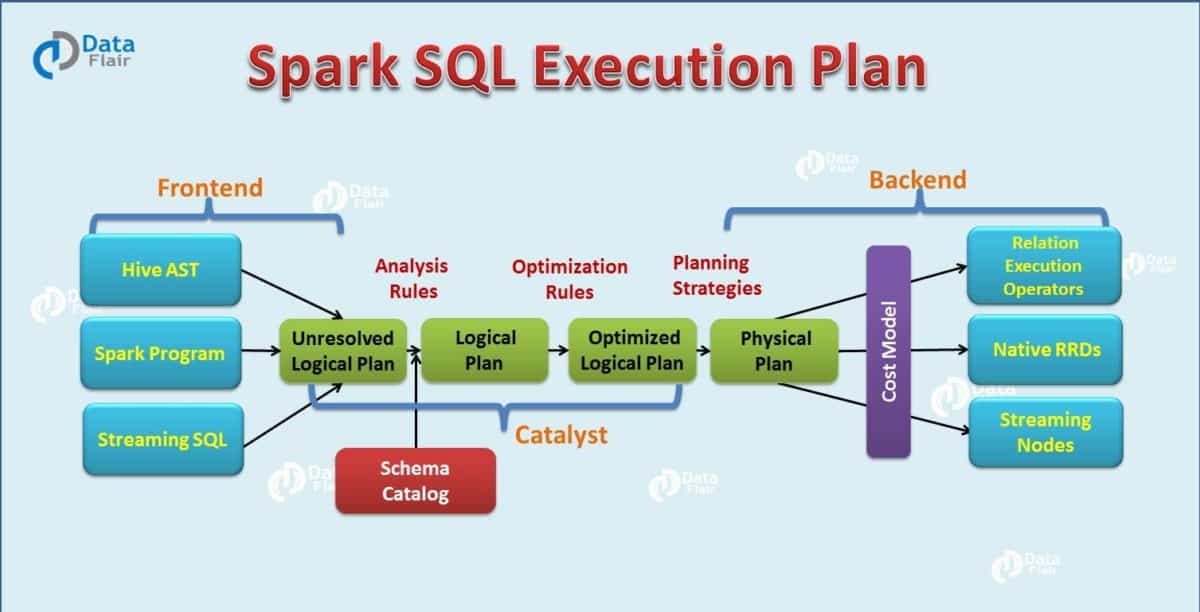
Dans les coulisses, Apache Spark utilise un optimiseur de requête appelé Catalyst qui examine les données et les requêtes afin de produire un plan de requête efficace pour la localisation et le calcul des données qui effectuera les calculs requis dans le cluster. À l’époque d’Apache Spark 2.x, l’interface Spark SQL des dataframes et des datasets (essentiellement un dataframe typé qui peut être vérifié au moment de la compilation pour être correct et tirer parti des optimisations de mémoire et de calcul au moment de l’exécution) est l’approche recommandée pour le développement . L’interface RDD est toujours disponible, mais n’est recommandée que si vous avez des besoins qui ne peuvent pas être couverts dans le paradigme Spark SQL.
Spark MLlib

Apache Spark regroupe également des bibliothèques pour appliquer les techniques d’apprentissage automatique et d’analyse graphique aux données à grande échelle. Spark MLlib comprend un framework pour créer des pipelines d’apprentissage automatique, permettant une implémentation facile de l’extraction de l’information, des sélections et des transformations sur tout l’ensemble de données structuré. MLLib est livré avec des implémentations distribuées d’algorithmes de clustering et de classification tels que le clustering k-means et les forêts aléatoires qui peuvent être facilement et rapidement permutées dans les pipelines personnalisés. Les modèles peuvent être formés par des scientifiques de données dans Apache Spark en utilisant R ou Python, sauvegardés en utilisant MLLib, puis importés dans un pipeline basé sur Java ou Scala pour une utilisation en production.
Notez que si Spark MLlib couvre l’apprentissage automatique de base incluant la classification, la régression, le clustering et le filtrage, cela n’inclut pas les fonctionnalités de modélisation et de formation des réseaux de neurones profonds. Cependant, Deep Learning Pipelines est en cours d’être couvert.
Spark GraphX
Spark GraphX est livré avec une sélection d’algorithmes distribués pour traiter les structures de graphe, y compris une implémentation du PageRank de Google. Ces algorithmes utilisent l’approche RDD de Spark Core pour modéliser les données ; le package GraphFrames vous permet de faire des opérations graphiques sur des dataframes, en profitant notamment de l’optimiseur Catalyst pour les requêtes graphiques.
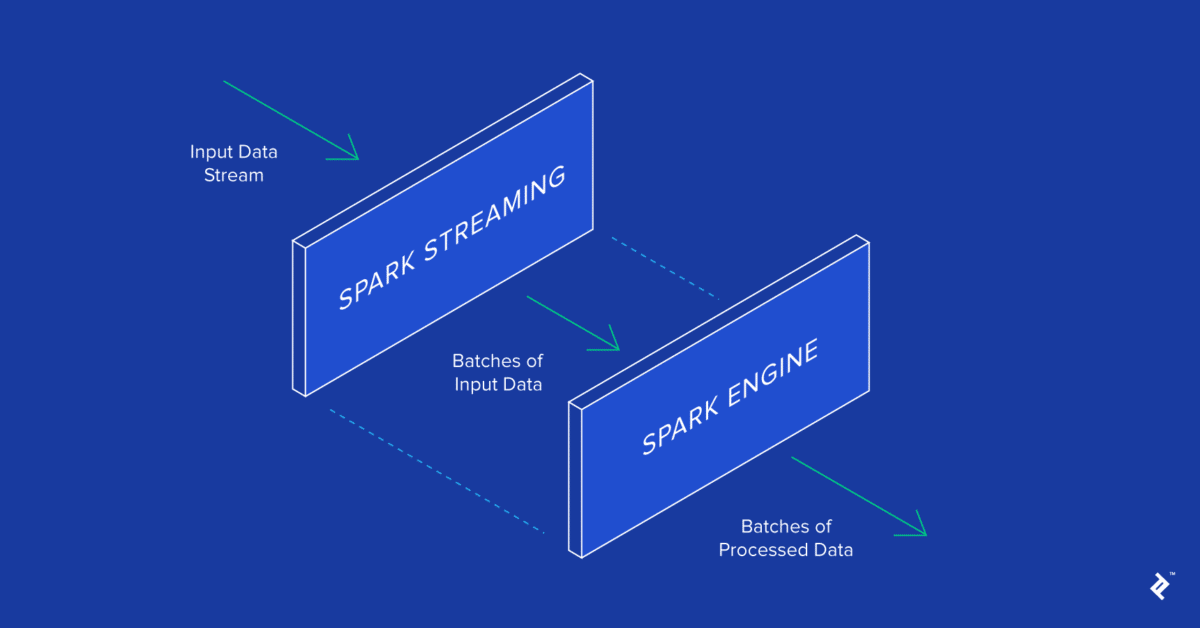
Spark Streaming
Spark Streaming a été l’un des premiers compléments d’Apache Spark qui l’a aidé à gagner du terrain dans des environnements nécessitant un traitement en temps réel ou en temps quasi réel. Auparavant, le traitement par lots et par flux dans le monde d’Apache Hadoop étaient des choses séparées. Vous devez écrire du code MapReduce pour vos besoins de traitement par lots et utiliser quelque chose comme Apache Storm pour vos besoins de streaming en temps réel. Cela conduit évidemment à des bases de code disparates qui doivent être synchronisées pour le domaine d’application, bien qu’elles soient basées sur des frameworks complètement différents, nécessitant des ressources différentes et impliquant des préoccupations opérationnelles différentes pour les exécuter.
Spark Streaming a étendu le concept d’Apache Spark de traitement par lots en streaming en décomposant le flux en une série continue de microbatches, qui pouvaient ensuite être manipulées à l’aide de l’API Apache Spark. De cette manière, le code dans les opérations de traitement par lots et par flux peut partager (le plus souvent) le même code, s’exécutant sur le même environnement, réduisant ainsi les frais généraux du développeur et de l’opérateur. Ainsi, tout le monde gagne.
Une critique de l’approche Spark Streaming est que la microbatching, dans les scénarios où une réponse à faible latence aux données entrantes est requise, peut ne pas être en mesure d’égaler les performances d’autres frameworks de streaming, comme Apache Storm, Apache Flink et Apache Apex, tous utilisent une méthode de streaming pur plutôt que des microbatches.
Structured Streaming

Structured Streaming (ajouté dans Spark 2.x) représente à Spark Streaming ce que Spark SQL était aux API Spark Core : une API de plus haut niveau et une abstraction plus facile pour l’écriture d’applications. Dans le cas de Structure Streaming, l’API de niveau supérieur permet essentiellement aux développeurs de créer des dataframes et des ensembles de données en continu infinis. Il résout également certains problèmes très réels auxquels les utilisateurs ont été confrontés dans le framework précédent, notamment en ce qui concerne les agrégations d’événements et la livraison tardive des messages. Toutes les requêtes sur les flux structurés passent par l’optimiseur de requêtes Catalyst et peuvent même être exécutées de manière interactive, permettant aux utilisateurs d’effectuer des requêtes SQL sur les données de streaming en direct.
Structured Streaming est encore une partie assez récente d’Apache Spark, ayant été marqué comme prêt à être utilisé dans la version 2.2 de Spark. Cependant, Structured Streaming est l’avenir des applications de streaming avec la plate-forme, donc si vous construisez une nouvelle application de streaming, vous devez utiliser Structured Streaming. Les anciennes APIs Spark Streaming continueront à être prises en charge, mais le projet recommande de passer à Structured Streaming, car la nouvelle méthode rend l’écriture et la maintenance du code de diffusion beaucoup plus supportables.
Quelle est la prochaine étape pour Apache Spark ?

Tandis que Structured Streaming fournit des améliorations de haut niveau à Spark Streaming, il mise actuellement sur le même schéma de microbatching pour gérer les données de streaming. Cependant, l’équipe d’Apache Spark travaille pour apporter la diffusion continue sans microbatching à la plate-forme, ce qui devrait résoudre de nombreux problèmes de gestion des réponses à faible latence (ils prétendent jusqu’à 1ms, ce qui serait très impressionnant). Mieux encore, parce que Structured Streaming se base sur le moteur de Spark SQL, tirer profit de cette nouvelle technique de streaming ne nécessitera aucun changement de code.
En plus d’améliorer les performances de streaming, Apache Spark ajoutera un support pour l’apprentissage en profondeur via Deep Learning Pipelines. En utilisant la structure de pipeline existante de MLlib, vous serez en mesure de construire des classificateurs en quelques lignes de code, ainsi que d’appliquer des graphes Tensorflow personnalisés ou des modèles Keras aux données entrantes. Ces graphiques et modèles peuvent même être enregistrés en tant que fonctions UDF Spark SQL personnalisées (fonctions définies par l’utilisateur) afin que les modèles d’apprentissage en profondeur puissent être appliqués aux données dans le cadre des instructions SQL.
Aucune de ces fonctionnalités n’est prête pour la production en ce moment, mais étant donné le rythme de développement rapide que nous avons connu dans Apache Spark par le passé, elles devraient être prêtes en prime time cette année.




