
En 2004, les activités d’Amazon dépassaient déjà les limites de leur infrastructure de base de données Oracle. Afin de développer l’activité en pleine croissance, AWS a conçu un magasin de valeurs-clés interne primé – Amazon Dynamo – pour répondre à leurs exigences de performances, d’évolutivité et de fiabilité.
Amazon Dynamo sous-tend maintenant une grande partie d’Amazon.com et a défini une toute nouvelle catégorie de bases de données de magasin de valeurs-clés – “NoSQL”. En 2012, AWS a annoncé la disponibilité de DynamoDB en tant que service de données NoSQL entièrement géré pour les clients avec la promesse d’une évolutivité transparente.

Pourquoi utiliser DynamoDB ?
Alors que Dynamo célèbre son dixième anniversaire l’année dernière, AWS devrait envisager un service complémentaire appelé “WhynamoDB”. Chaque fois qu’un développeur tente de provisionner une nouvelle table DynamoDB, le service apparaît dans AWS Console et demande simplement : “Pourquoi ?”.
La réponse à “pourquoi utiliser DynamoDB ?” n’est pas aussi simple que la promesse marketing de l’évolutivité transparente.
Un certain nombre d’ingénieurs et de développeurs ont été interviewés sur leurs expériences avec le service de base de données. Aussi génial que DynamoDB, et aussi excitant que ses succès, il a également laissé beaucoup d’implémentations échouées dans son sillage.
Afin de comprendre ce qui fait que certaines implémentations de DynamoDB réussissent et d’autres échouent, nous devons examiner la tension essentielle entre les deux grandes promesses de DynamoDB – la simplicité et l’évolutivité.
DynamoDB est simple – jusqu’à ce qu’il ne soit pas évolué

Il ne faut vraiment pas exagérer à quel point il est facile de commencer à lancer des données dans DynamoDB. L’équipe AWS a fait un excellent travail d’abstraction de la complexité – vous n’avez pas besoin de vous connecter à un studio de gestion, vous n’avez pas à vous soucier des pilotes de base de données, vous n’avez pas besoin de configurer un cluster.
Pour commencer avec DynamoDB, il suffit de tourner un bouton pour la capacité provisionnée, récupérer votre SDK préféré, et commencer à lancer JSON.
Avec cet ensemble de fonctionnalités, il n’est pas étonnant que DynamoDB soit particulièrement attractif pour les développeurs d’applications “sans serveur”. Après tout, beaucoup d’applications sans serveur commencent en tant que prototypes, donnant la priorité à la rapidité de livraison et à la configuration minimale. Pourquoi se tromper avec un datastore relationnel alors que vous ne savez même pas à quoi ressemblera votre modèle de données final ?
Dans ce cas, nous devons faire une grande distinction – sans jeu de mots. DynamoDB peut être simple et que les internautes peuvent facilement interagir avec, mais une architecture soutenue par DynamoDB n’est absolument pas simple à concevoir.
DynamoDB est un magasin de valeurs-clés. Cela fonctionne très bien si vous récupérez des enregistrements individuels basés sur les recherches clés. Les requêtes complexes ou les analyses nécessitent une indexation minutieuse et sont délicates ou tout simplement impropres à l’écriture, même si vous n’avez pas une très grande quantité de données et même si vous connaissez les principes de conception de NoSQL.
Cette dernière partie concerne le plus grand problème, bien sûr – il y a énormément de développeurs qui ne connaissent pas grand-chose sur NoSQL comparé à la conception de base de données relationnelle classique. De plus, l’expérience antérieure de NoSQL n’est pas toujours positive. Des équipes d’ingénieurs ont été contrariés quand ils ont apporté un tas d’attentes de MongoDB, une base de données de documents, à leur implémentation de DynamoDB.
Alors, lorsque vous combinez des développeurs inexpérimentés, il y aura l’absence d’un plan clair pour modéliser un ensemble de données dans DynamoDB et un service de base de données géré qui facilite l’acquisition de nombreuses données non structurées, vous pouvez ainsi vous retrouver avec une solution qui échappe à tout contrôle même à petite échelle.
Lynn Langit, une consultante en données cloud expérimentée dans les trois grands clouds publics, a vu assez de ces implémentations bâclées pour se méfier légitimement des entreprises qui s’appuient sur des solutions NoSQL comme DynamoDB.

Lors de l’interview de Lynn pour la série “Superhéros sans serveur”, elle a partagé une histoire sur le déplacement d’un client de DynamoDB vers Aurora – le service de base de données relationnelle AWS – même si l’architecture de référence AWS pour leur projet utilisait DynamoDB.
Le client avait toutes sortes de problèmes et un jour, j’ai décidé de passer à Aurora. Ils ont paniqué tout le monde – ils ont dit : ‘Qu’est-ce que tu fais ?’ J’ai dit : ‘Que faisons-nous ? Nous expédions un produit. “Et nous l’avons fait.”
Lynn Langit
La première loi de DynamoDB
Supposons qu’une implémentation DynamoDB sera plus difficile que d’utiliser une base de données relationnelle que vous connaissez déjà.
Une base de données relationnelle fera tout ce dont vous avez besoin à petite échelle. La mise en place initiale de DynamoDB peut prendre un peu plus de temps, mais les conventions bien établies d’une implémentation SQL peuvent vous épargner beaucoup de temps perdu.
Ce n’est pas parce que DynamoDB est une mauvaise technologie – mais parce que c’est nouveau pour vous, et que les choses qui semblent “faciles” et “pratiques” vous font complètement casser la tête si vous ne les comprenez pas.
DynamoDB est évolutif – jusqu’à ce qu’il ne soit pas simple
Maintenant, explorez l’autre extrémité du spectre – il y a de très grandes tables DynamoDB. Pour cet article, plusieurs clients satisfaits ayant une latence inférieure à la seconde avec des milliards d’enregistrements dans leurs tables DynamoDB ont été interrogés. DynamoDB promet des performances constantes à une échelle essentiellement infinie, limitée uniquement par la taille physique du cloud AWS.
Sans exception, ces clients représentent bien des cas d’utilisation canonique de DynamoDB : effectuer des recherches de valeur-clé sur des enregistrements bien répartis, éviter les requêtes complexes et, surtout, limiter les clés que vous accédez fréquemment.
Traiter avec des clés à forte fréquentation est sans aucun doute le “gotcha” le plus connu de DynamoDB. Le problème avec les clés à forte fréquentation est bien expliqué dans de nombreux articles, y compris dans les documents du guide du développeur DynamoDB.
Bien que DynamoDB puisse évoluer indéfiniment, vos données ne sont pas stockées sur un serveur unique, magique et en constante expansion. Au fur et à mesure que vos données dépassent la capacité d’un seul fragment DynamoDB, ou « partition » (jusqu’à 10 Go), il est divisé en morceaux, chaque fragment se trouve sur une partition différente.
Si vous avez une clé « à forte fréquentation » dans l’ensemble de vos données – un enregistrement particulier auquel vous accédez fréquemment – vous devez vous assurer que la capacité allouée sur votre table est suffisamment élevée pour gérer toutes ces requêtes.
Le “gotcha” est que vous ne pouvez provisionner la capacité de DynamoDB au niveau de la table entière – pas par partition – et la capacité est répartie entre les partitions à l’aide d’une formule assez ridicule. Par conséquent, votre capacité de lecture et d’écriture sur un enregistrement donné est beaucoup plus petite que votre capacité globale allouée.
Donc, si votre application utilise trop d’unités de capacité de lecture (RCU) sur une seule clé, vous devez soit surprovisionner toutes les autres partitions (coûteuses), générer une tonne d’erreurs “Débit dépassé” (pas idéal), ou trouver comment réduire l’accès à cette clé.
Un point à retenir ici est que DynamoDB n’est pas nécessairement adapté aux ensembles de données qui ont un mélange d’enregistrements à forte et à faible fréquentation. Mais à une évolution suffisamment grande, chaque ensemble de données a un tel mélange. Bien sûr, vous pouvez diviser les données en différentes tables – mais si vous le faites, vous avez perdu l’avantage d’évolutivité que DynamoDB était censé fournir en premier lieu.
Un blog a récemment publié sur ce sujet intitulé “The Million Dollar Engineering Problem“. Il a montré comment Segment a considérablement réduit sa facture AWS en corrigeant le surprovisionnement de DynamoDB lié aux clés à forte fréquentation. La partie la plus intéressante de cet article est les graphiques “heatmap” montrant exactement quelles partitions avaient causé ces perturbations.
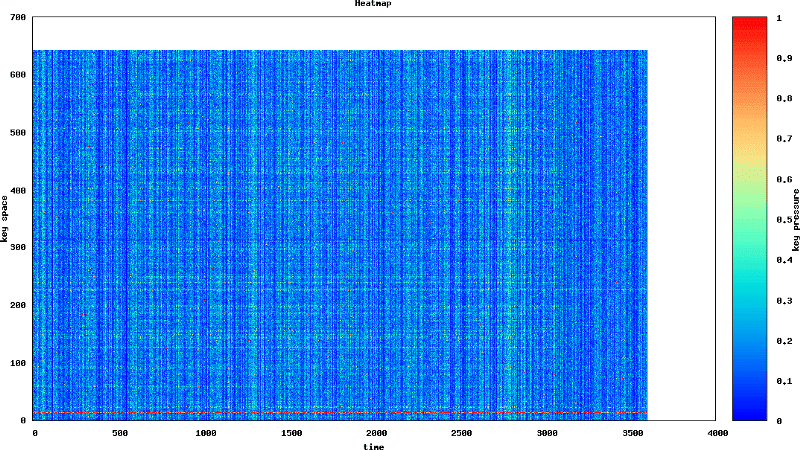
Maintenant, si vous lisez les petits caractères, ces superbes graphismes proviennent des outils internes d’AWS, et non de n’importe quel monitoring que Segment a pu faire par lui-même. En d’autres termes, un agent de Segment a dû téléphoner à l’équipe de DynamoDB afin d’obtenir une observabilité dans les problèmes de base de données.
Même à ce moment-là, leur stratégie de blocage des clés perturbateurs consistait à encapsuler les appels DynamoDB dans une logique try/catch – et exécuter une logique de trace personnalisée si une clé particulière a fait trébucher une exception de débit.
En effet, Segment a dû lutter contre le problème de clés à forte fréquentation avec un bandeau sur les yeux, et c’est là que nous revenons à la tension entre la simplicité et l’évolution.
DynamoDB est conçu comme une boîte noire avec très peu de contrôles accessibles à l’utilisateur. Cette approche le rend facile à utiliser lorsque vous venez juste de commencer. Mais à l’évolution de la production – lorsque ces limites régissent votre vie – parfois vous avez désespérément besoin de plus d’informations sur la raison pour laquelle vos données se comportent mal.
Vous avez besoin d’un tout petit peu de complexité compatissante.
La deuxième loi de DynamoDB
À une évolution plus grande, l’utilisabilité de DynamoDB est limitée par sa propre simplicité.
Ce n’est pas un problème avec l’architecture de Dynamo. C’est un problème avec ce que AWS a choisi d’exposer via le service de DynamoDB.
À ce stade, nous n’avons pas encore abordé la question des sauvegardes et restaurations – quelque chose que DynamoDB ne supporte pas nativement et qui devient terriblement compliqué à grande échelle. L’incapacité à sauvegarder 100 To de données DynamoDB était apparemment une grande raison pour laquelle Timehop a récemment quitté le service.
Si ce n’est pas DynamoDB, alors comment faire ?
Donc, si DynamoDB n’est qu’une des nombreuses options plausibles à petite échelle, et a une viabilité limitée en tant que service à grande échelle – en quoi est-il bon ?
Si vous demandez à AWS, il répondra que sur presque tout. Après tout – Werner Vogels dit que la conception originale de Dynamo pourrait gérer environ 90% des charges de travail d’Amazon.com.
À l’exception de certains cas particuliers comme les analyses BI ou les transactions financières, il est vrai que vous pouvez redéfinir n’importe quelle application pour sauvegarder les données des relations de l’entreprise en dehors de la base de données, stocker l’état dans une table K/V et utiliser une architecture événementielle au contenu de votre choix.
Mais, comme disait un professeur en informatique, il est également vrai que « juste parce que tu peux, ne veut pas dire que tu devrais le faire ».
Si vous ne comprenez pas parfaitement pourquoi vous utilisez DynamoDB dès le départ, vous risquez de finir comme Ravelin en train de s’embourber dans les réécritures de code jusqu’à finalement atterrir sur une solution qui fonctionne plus ou moins – mais vous détestez quand même.
La troisième loi de DynamoDB
C’est pourquoi Lynn Langit a plus ou moins abandonné NoSQL comme solution pour les petites et moyennes entreprises. C’est pourquoi Timehop est passé de DynamoDB à Aurora, et c’est pourquoi une autre société bien connue et interviewée est passée à “un cluster géant ElasticSearch “.
C’est aussi pourquoi DynamoDB a de nombreuses études de cas de clients satisfaits de grandes marques. Non pas parce que l’une de ces technologies est uniformément meilleure qu’une autre – mais parce que les ingénieurs de chaque entreprise, avec leurs cas d’utilisation spécifiques et leurs niveaux d’expertise, ont pu fournir la valeur commerciale plus rapidement et efficacement avec des solutions différentes.
Introduction à Amazon WhynamoDB
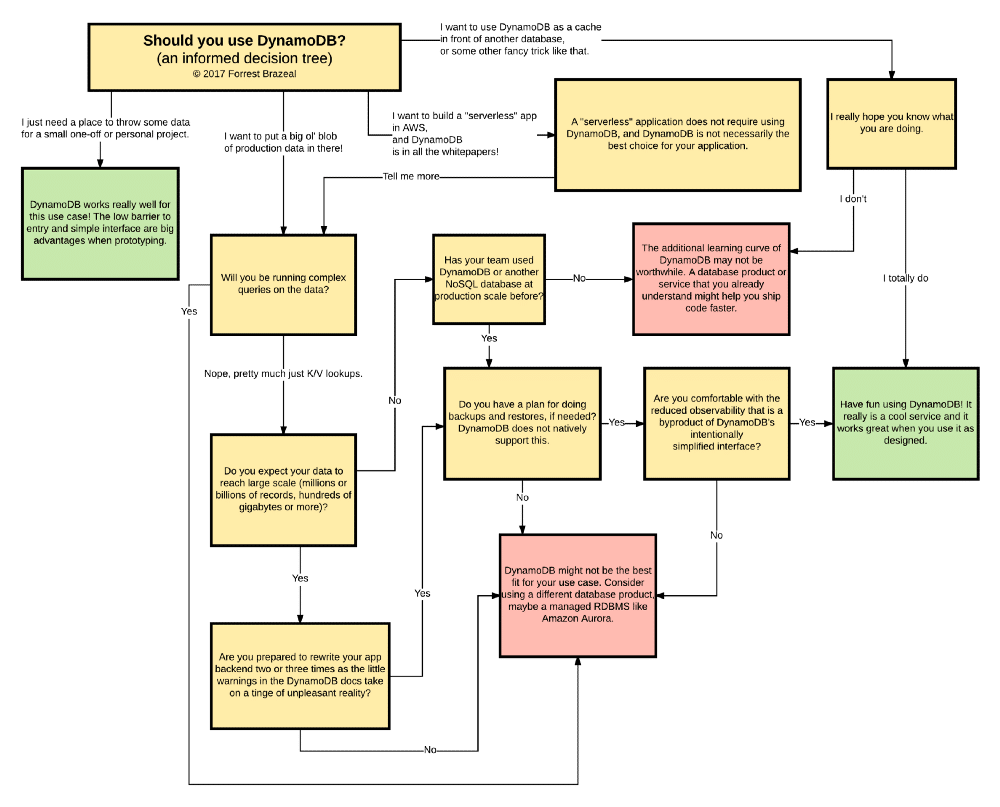
À un moment donné, Amazon peut annoncer la publication du service WhynamoDB qui demande « pourquoi vous approvisionnez une table DynamoDB ? ». En cours de lancement, on a créé cet arbre de décision pratique qui vous guide à travers le service WhynamoDB.
Quelle est votre expérience et vos avis sur DynamoDB ? Faites-nous entendre ce que vous pensez dans les commentaires ci-dessous !
Si vous avez apprécié cet article, n’oubliez pas de le partager.




