

Mis à jours 23 février 2020 Débarrassez-vous de vos problèmes d’infrastructure grâce à notre guide sur les sans serveurs ou encore Serverless en anglais et aux options de cloud public et sur site qui alimentent ses possibilités.
L’informatique sans serveur (serverless )constitue une excellente opportunité pour les développeurs qui cherchent à se libérer du fardeau de l’infrastructure. En faisant abstraction de tout sauf d’un bloc de code, le modèle sans serveur permet aux développeurs d’itérer plus rapidement et de déployer de nouveaux codes, ce qui permet aux petites équipes disposant de budgets réduits de faire ce que seules les grandes entreprises pouvaient faire auparavant. Ou, comme l’a récemment déclaré Mat Ellis, fondateur et PDG de Cloudability, dans un épisode de CloudCast, « Le sans serveur tente d’industrialiser l’impact des développeurs ».
Bien sûr, en arrière-plan, les serveurs existent encore. Mais, les architectures sans serveur sont sans état. Ils font leur travail en exécutant un peu de logique – une fonction – et en appelant les autres services à faire tout ce dont ils ont besoin. Si vous êtes un développeur qui construit principalement des applications utilisant des services via des API ou qui doit répondre à des événements, l’architecture sans serveur peut s’avérer être le moyen le plus simple, le plus rapide et le moins risqué pour ce faire.
Dans cet article, nous décrivons ce que signifie réellement l’architecture sans serveur, nous proposons une comparaison détaillée des principales options de cloud public.
Avec Serverless (sans serveur), tout tourne autour de la fonction

Serverless est un modèle de service de cloud computing qui, comme IaaS, PaaS, SaaS, BaaS et CaaS, dépend d’un accès omniprésent, pratique et à la demande à un pool partagé dynamique de ressources réseau, de stockage et de calcul configurables. Serverless adopte cependant, une approche différente sur l’utilisation de ces ressources. Il n’y a pas de définition convenue de l’informatique sans serveur, mais un manifeste sur le concept a fait son apparition. Avec sans serveur, les fonctions sont l’unité de déploiement. Aucune machine, ni machine virtuelle ni conteneur n’est visible pour le programmeur.
AWS Lambda, Azure Functions et Google Cloud Functions figurent parmi les principaux services disponibles pour le sans serveur. Dans le cloud, “FaaS” (functions as a service) peut être un meilleur terme. Et quand on parle de « fonction », c’est vraiment une fonction. Voici un exemple AWS Lambda codé dans Node.js :
exports.myHandler = function(event, context, callback) { console.log("value1 = " + event.key1); // do stuff callback(null, "some success message"); }
C’est tout. Téléchargez la fonction et reliez-la à une demande ou à un événement. Lorsque votre fournisseur d’hébergement sans serveur (dans ce cas, AWS) détecte qu’une demande a été effectuée (par exemple, un appel REST) ou qu’un événement s’est produit (par exemple, un fichier est ajouté à un compartiment S3), votre fonction est appelée avec les arguments passés, et vos paramètres de retour seront transmis comme résultat. C’est plus compliqué en pratique, bien sûr, car vous pouvez ajouter des restrictions de sécurité, par exemple, mais c’est l’essentiel.
Votre fonction peut être écrite dans n’importe quelle langue prise en charge par votre fournisseur. Tout ce que vous devez faire est de mapper une demande entrante ou un événement dans un appel de fonction. Chaque fournisseur a son propre ensemble de langues, de conventions, de procédures, de coûts, de capacités et de restrictions pris en charge (voir le tableau ci-dessous). Mais, c’est ce que le Manifeste Serverless veut dire par “apportez votre propre code”.
Votre fonction peut être arbitrairement complexe et elle peut appeler des bibliothèques incluses ou des services externes via une API. Pour être évolutive, une fonction sans serveur ne doit utiliser que des services eux-mêmes évolutifs.
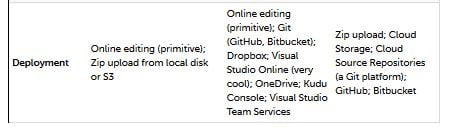
Selon le fournisseur, le code peut être écrit directement dans un éditeur en ligne ou être téléchargé en tant que fichier de code, fichier .zip ou .jar, ou conteneur. Ceci est également un inconvénient de sans serveur, car l’outil de téléchargement et de gestion de votre code à travers le cycle de publication n’est toujours pas très bon, bien que de nombreux frameworks interviennent pour combler le vide.
Bien sûr, le code ne peut vraiment pas être arbitrairement complexe. Il existe des restrictions dépendantes du fournisseur. Chaque hôte a une taille de téléchargement de code maximale (50 Mo pour AWS Lambda, par exemple). Il a également une durée d’exécution maximale de la fonction (entre 1 et 300 secondes pour AWS Lambda). Chaque fonction est également limitée dans la quantité de la mémoire disponible et la puissance de la CPU utilisée. Voulez-vous plus de mémoire, un meilleur processeur ou un temps d’exécution plus long ? Vous payez plus. La facturation est un autre point de différence entre les fournisseurs, comme nous le verrons ci-dessous.
Derrière le rideau : pas de temps mort

Dans les coulisses, il y a des serveurs, bien sûr, mais en tant que développeur, vous n’avez jamais besoin de penser à eux. Tout ce que vous devez savoir est votre fonction. Vous n’avez plus à gérer la planification de la capacité, le déploiement, la mise à l’échelle, l’installation, les correctifs, etc. Tout ceci est souvent vu comme NoOps ou LessOps, mais c’est vraiment DifferentOps. Le Code doit encore être organisé, développé, construit, testé, versionné, publié, enregistré et surveillé.
Puisque tout ce que vous voyez est la fonction, votre fournisseur est en charge de l’activation de vos fonctions en réponse à toute demande ou événement. Lorsqu’une requête arrive et qu’une instance libre de la fonction n’est pas disponible, le code doit être alloué à un serveur et démarré. En tant que développeur, vous ne faites rien. C’est à votre fournisseur de s’assurer qu’il y a suffisamment de capacité pour gérer la charge. Bien sûr, dans le cas d’un scénario de démarrage à froid, le temps de latence est l’un des inconvénients de Serverless.
Avec Serverless, vous payez pour la consommation et n’êtes facturé que si votre service fonctionne. Vous ne payez jamais pour le temps de calcul inactif. Cela concerne de nombreuses situations. Vous pouvez construire une infrastructure entière sans payer un seul centime. Les coûts opérationnels, de développement et de mise à l’échelle sont tous réduits.
Comparez cela avec PaaS/IaaS, où vous payez pour la capacité. Un fournisseur PaaS gérera les serveurs pour vous, mais votre application a des processus de longue durée que vous payez toujours, même s’ils sont inactifs. La capacité peut être gérée en construisant un système d’autoscaling sensible à la charge, mais vous paierez toujours pour un certain excès de capacité.
Et l’état alors ?
Puisque tout ce que vous voyez est une fonction, il n’y a pas de place pour stocker l’état. Lorsqu’une fonction est exécutée, ses ressources de calcul peuvent être récupérées et réutilisées. L’état doit être stocké dans un autre service comme une base de données ou un cache.
Pour contrôler les coûts de facturation, les fournisseurs placent un temps d’exécution maximal sur une fonction. Actuellement, il s’agit de cinq minutes pour les fonctions AWS Lambda et Azure. Il y a un inconvénient aux limites d’exécution. Par exemple, que faire si vous mettez à jour une base de données ? Ou votre fonction fait beaucoup d’appels à d’autres services pour retourner un résultat ? Ou votre fonction a beaucoup d’entrée à traiter ? Ces opérations peuvent prendre beaucoup plus de temps que cinq minutes dans certains cas.
À moins que votre fonction ne soit simple, les fonctions doivent être codées en tant que services sans état, idempotents, pilotés par les événements et par une machine d’état contenant des données dans une mémoire persistante entre des invocations. Cela peut devenir compliqué. Votre cloud normal approche toujours. Divisez les entrées en lots et placez-les dans une file d’attente, par exemple.
Pour vous aider, AWS a créé un nouveau service appelé Step Functions qui implémente une machine d’état et permet aux fonctions de durer indéfiniment. Vraiment, AWS Lambda devrait être meilleur plutôt que d’exiger un service complètement différent et coûteux.
Statistiques et journalisation : un défi au mieux

Bien que l’interface serveur soit réduite à une fonction unique, parfois appelée nanoservice, la complexité est toujours conservée. Avec PaaS, l’unité atomique de calcul est l’application. Cela a des avantages et des inconvénients. Si une application est volumineuse, elle peut être lente à démarrer et à s’arrêter ; c’est peut être difficile d’évoluer en réponse à la demande ; c’est peut être difficile d’être facturé à un niveau granulaire. Mais, PaaS est également facile à gérer, surveiller et déboguer.
En répartissant le code sur un nombre potentiellement important de fonctions, Serverless peut être très difficile à déboguer. La trace pour les flux logiques est répartie sur un certain nombre de fichiers journaux différents et il n’y a pas de connexion entre les appels. La journalisation et les statistiques sont obligatoires, mais ce n’est pas suffisant. L’outillage dans ce domaine doit s’améliorer.
Fournisseurs de Serverless (sans serveur)

Comment commencer ? Il y a un certain nombre d’options pour commencer à travailler avec Serverless. Les deux grandes options sont : utiliser le cloud public et construire avec une solution sur site.
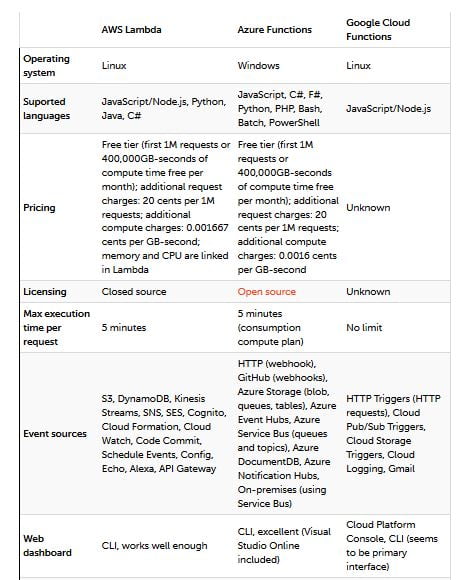
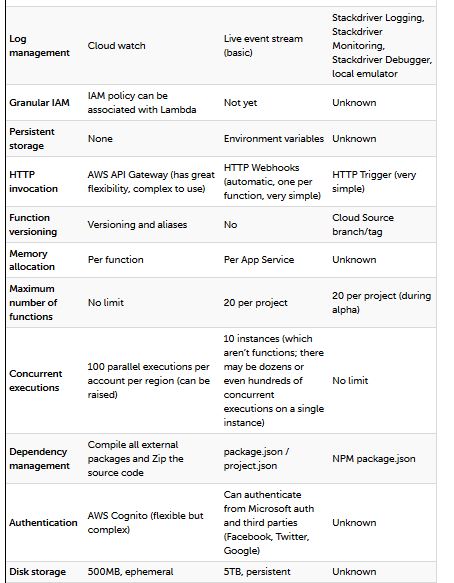
Serverless est devenu un enjeu pour tout cloud public, de sorte que tous les principaux fournisseurs développent leur propre produit. Amazon a AWS Lambda, qui est disponible de façon généralisée (GA) depuis avril 2015. Microsoft a Azure Functions, qui est GA depuis novembre 2016. Google a Google Cloud Functions, qui est en alpha fermé.
En ce qui concerne votre choix entre les trois, si vous êtes déjà sur le cloud public, il est préférable d’utiliser le produit de votre fournisseur actuel. Une grande partie de l’utilité de Serverless est la richesse des services disponibles et des événements que vous pouvez consommer. Ces choix sont les meilleurs dans votre cloud. Mais si vous vous lancez dans le cloud et que la stabilité est importante, alors AWS Lambda a été le plus long et le choix le plus sûr jusqu’à présent.
Pour AWS Lambda, les fonctions sont indépendantes, bien qu’en pratique, elles soient souvent gérées en groupes à l’aide d’un framework tel que Serverless. Vous êtes facturé en fonction du nombre de demandes pour vos fonctions et d’heures d’exécution de votre code. Si vous voulez plus de CPU, vous devez allouer plus de mémoire.
Avec Azure Functions, une application de fonction est composée d’une ou de plusieurs fonctions individuelles gérées conjointement par Azure App Service. Une Application de Fonction (Function App) peut utiliser un Plan d’hébergement de Consommation ou un Plan d’hébergement App Service. Avec un Plan de Consommation, une Application de Fonction (Function App) évolue automatiquement et vous payez en fonction de la taille de la mémoire et du temps d’exécution total pour toutes les fonctions mesurées en giga-octets-secondes. L’utilisation de la facturation du plan d’hébergement App Service ressemble beaucoup plus à EC2.
Puisque Google Cloud Functions est toujours en alpha fermé, une grande partie de la manière dont les fonctions fonctionnent et sont facturées reste inconnue. Nous savons qu’il existe deux types de fonctions : les fonctions HTTP et les fonctions d’Arrière-plan. Les fonctions HTTP sont directement appelées via HTTP(S). Les fonctions d’Arrière-plan sont appelées indirectement via un message sur un sujet Google Cloud Pub/Sub ou une modification dans un compartiment Google Cloud Storage.
Serverless sur site
L’hébergement sans serveur dans votre propre centre de données n’est pas encore simple, bien que cela devienne plus facile et qu’il existe un certain nombre d’options. Cependant, vous devez être prêt à mettre en place et à maintenir l’infrastructure.
C’est un espace en mouvement rapide. Les vendeurs tentent de se positionner, essayant de se tailler un marché dans l’ombre des géants du cloud public. Avancer prudemment ! Toutes les promesses de portabilité des applications doivent être considérées avec scepticisme.
Azure Stack
Si votre objectif est de fonctionner sur site comme le cloud public, Azure Stack semble être le meilleur choix. Dans quelle mesure fonctionnera-t-il ? C’est à déterminer, mais il est très prometteur et constitue une différenciation importante entre les fournisseurs de cloud.
IBM OpenWhisk
OpenWhisk est le logiciel FaaS d’IBM qui peut être hébergé ou sur site. Il possède une passerelle API, un support natif Swift et Node.js, ainsi qu’une prise en charge des images Docker. Il est susceptible de voir plus d’adoption cette année, car c’est l’un des produits les mieux soutenus.
Iron.io
Iron.io a été le premier fournisseur sans serveur, mais doit maintenant faire son chemin dans le monde de grands fournisseurs de cloud. Il offre deux options : IronFunctions et Project Kratos.
Project Kratos est une stratégie d’adoption : il permet aux entreprises d’exécuter la fonctionnalité AWS Lambda dans n’importe quel fournisseur de cloud, ainsi que sur site, en éliminant le verrouillage des fournisseurs.
IronFunctions est la stratégie d’extension : C’est une plate-forme open source sans serveur/FaaS basée sur Docker que vous pouvez utiliser n’importe où : sur des clouds publics, privés et hybrides, même sur votre propre ordinateur portable.
Fission.io
Fission.io est une nouvelle approche intéressante du sans serveur qui utilise Kubernetes pour son infrastructure cloud. Kubernetes prend en charge la gestion des clusters, la planification et la mise en réseau. Il y a une ligne de pensée que Kubernetes, parce qu’il a une communauté de développeurs dynamique et productive, sera le gagnant en tant qu’infrastructure cloud open source. La construction d’un produit sans serveur sur Kubernetes permet une pile alternative intéressante sur site.
OpenStack
Actuellement, OpenStack n’a pas de support natif pour FaaS, mais il a Project Picasso. Ce dernier a deux composants principaux : Picasso API et IronFunctions. Picasso utilise le moteur de conteneur back-end fourni par IronFunctions.
Travaillez avec le vôtre
Serverless n’est pas dur à comprendre. Vous pouvez construire votre propre plate-forme sans serveur à partir de votre infrastructure actuelle et obtenir tous les avantages sans avoir à migrer vers une nouvelle pile. C’est une bonne option si vous ne voulez pas traiter votre centre de données comme s’il s’agissait d’un cloud.




