

Un guide d’architecte pour réduire les coûts au fur et à mesure que les clients grandissent.
Le développement d’une petite application mobile peut se faire très facilement – bien qu’il soit difficile de changer l’architecture sous-jacente une fois que l’application est opérationnelle. Avant le lancement, prenez le temps de préparer votre application mobile avec des services backend résilients qui s’adapteront à votre succès.
Avant toute chose, la préparation est la clé du succès.
– Alexander Graham Bell

L’architecture de votre application mobile doit être conçue de sorte que chaque composant backend évolue de manière indépendante et résiste aux défaillances, même au niveau du fournisseur de cloud.
Si possible, implémentez des technologies sans serveur (serverless). Cela permettra à vos services backend d’évoluer de manière efficace et automatique pour répondre à la demande, et de réduire vos coûts au fur et à mesure que vos clients grandiront.
Pour préparer le succès de votre application mobile, votre conception doit inclure chacun de ces six composants clés d’un backend sans serveur bien architecturé :
Numéro 1 : Calcul piloté par événement
Au fur et à mesure que les développeurs s’éloignaient des applications monolithiques pour créer des microservices construits au sein des conteneurs, cela permettait de déployer des modules individuellement. Cette approche a également permis à chaque équipe de développeurs de choisir le framework et le langage de programmation de leur choix.
Avec l’émergence des fonctions sans serveur (Serverless) AWS Lambda, un modèle encore plus efficace du calcul piloté par événement est désormais disponible pour les développeurs.
Avec sans serveur (Serverless), le client de l’application crée un événement qui déclenche une fonction à la demande. Par exemple, l’événement d’un client qui télécharge une image déclenchera une fonction pour exécuter une routine de traitement d’image.
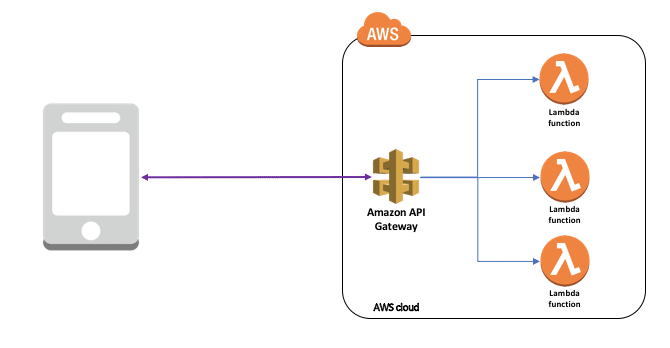
- Vous n’avez pas à vous soucier de la mise à l’échelle du calcul – seulement de votre application.
- Vous pouvez découpler les implémentations backend des déploiements frontend.
- Les problèmes au niveau du service, tels que la mise en cache, la surveillance et la journalisation, sont conservés au niveau de la passerelle API.
- L’authentification est gérée au niveau de la passerelle API, puis transmise aux fonctions Lambda individuelles.
- Les équipes individuelles peuvent être responsables du déploiement de leur propre code, y compris la sélection du langage de programmation.
- La passerelle API peut prendre en charge la gestion des versions, de sorte que les nouvelles versions ou les versions de test de l’API sont facilement implémentées.
Numéro 2 : Stockages de données sans serveur
Les données sont probablement l’un des premiers problèmes rencontrés par les développeurs lors de la mise à l’échelle d’un backend mobile. Quel que soit le stockage de données que vous décidez d’implémenter, vous devez isoler le backend pour garantir une meilleure expérience mobile.
La plupart des applications modernes sont écrites pour tirer parti des services Web RESTful pour accéder aux données. Pour les applications utilisant REST, il est recommandé de placer un ensemble de fonctions Lambda derrière une passerelle API pour accéder aux données.
Les applications les plus intelligentes tirent parti de GraphQL pour minimiser le transfert de données entre le client et le serveur. Pour GraphQL, utilisez un service géré tel que AWS AppSync pour fournir le service GraphQL et isoler les données.
AWS AppSync inclut également des fonctions spécifiques de synchronisation des données en temps réel collaboratives sur tous les types de données, ce qui offre une grande flexibilité au sein de votre application.
Concernant la base de données backend, il y a tellement de questions à répondre avant de commencer :
- Avez-vous besoin de bases de données relationnelles ou NoSQL ?
- Avez-vous besoin de données non structurées comme des images et des vidéos ?
- Quels sont les modèles et les types de requête?
- Avez-vous besoin d’un accès aux données hors ligne ?
- Quels scénarios collaboratifs en temps réel avez-vous besoin de prendre en charge ?
- Quels scénarios de basculement devez-vous prendre en charge ?
- Quel est votre plan pour l’échelle mondiale ?
AWS offre une gamme d’options de stockage sans serveur prenant en charge chacun des scénarios d’utilisation, chacun avec ses propres avantages et d’inconvénients.
- Amazon DynamoDB est une option NoSQL entièrement sans serveur, avec réplication automatique et basculement, et réplication de zone à disponibilité multiple intégrée. Il prend également en charge les tables globales pour assurer une portée véritablement mondiale. Cependant, il ne fournit pas d’opérations relationnelles standard telles que les jointures entre les tables.
- Aurora Serverless est un nouveau service de prévisualisation pour Amazon Aurora – une option de base de données évolutive avec les modes MySQL et PostgreSQL. La base de données augmentera ou réduira automatiquement la capacité en fonction des besoins de votre application, tout en offrant une connectivité SQL pour les besoins relationnels. La réplication à 6 voies est intégrée, ce qui permet une tolérance globale aux pannes.
- Parfois, la base de données n’a pas les capacités dont vos requêtes ont besoin. Cela se produit généralement avec la recherche en texte intégral, l’appariement flou, l’analyse des journaux et les exigences d’analyse géospatiale. Dans ce cas, complétez votre base de données avec Amazon Elasticsearch Service. Vous pouvez alimenter le service Elasticsearch directement à partir de la base de données à l’aide d’un déclencheur AWS Lambda.
- Le stockage Amazon S3 peut être utilisé pour les données non structurées telles que l’audio, la vidéo et les images. Il est facile à utiliser avec un simple service Web pour stocker et récupérer n’importe quelle quantité de données. Associez-le à un service Amazon CloudFront pour fournir des fonctionnalités CDN dans le monde entier.
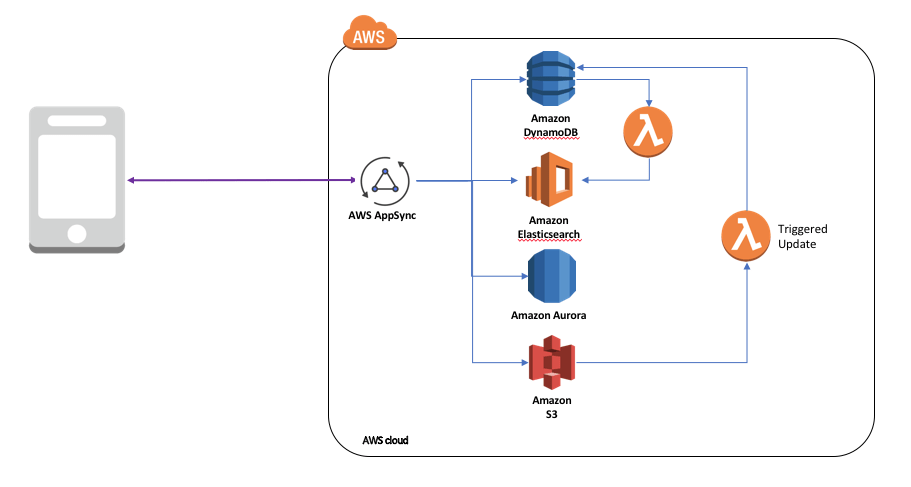
Vous utiliserez probablement plusieurs services de base de données pour votre application. Pour une application e-commerce classique, vous pouvez implémenter le catalogue avec une base de données NoSQL qui alimente un service Elasticsearch pour tirer parti des meilleures caractéristiques de recherche, telles que l’appariement flou et la recherche à facettes. Utilisez ensuite une base de données SQL pour le traitement des entrées de commande et stockez vos vidéos et images sur Amazon S3.
- Utilisez la source de données appropriée nécessaire pour la requête. Cela peut impliquer l’appariement de deux bases de données via des déclencheurs.
- Isolez l’application à partir des données backend à l’aide d’AWS AppSync – un service GraphQL géré.
- Stockez les ressources statiques telles que les images, la vidéo et l’audio dans Amazon S3 et diffusez le contenu en toute sécurité via Amazon CloudFront.
Numéro 3 : Gestion et Identité des utilisateurs

Il semble que chaque développeur souhaite utiliser sa propre solution d’identité pour prendre en charge les schémas d’authentification de type “nom d’utilisateur + mot de passe”.
Conseils de pro – vos utilisateurs ne veulent pas se souvenir d’un autre mot de passe.
Le but d’une solution de gestion et d’identité des utilisateurs est de sécuriser les ressources sur le backend, de minimiser les désaccords avec vos utilisateurs et de s’adapter à l’évolution de votre application.
Cela indique l’utilisation d’un service. Sur AWS, c’est Amazon Cognito.
En plus de résoudre le problème de base du répertoire des utilisateurs, Cognito prend également en charge les mécanismes de connexion sociale OpenID Connect, SAML, OAuth 2.0, Facebook et Google. Choisissez simplement le fournisseur de services sociaux approprié à votre application et utilisez-le pour l’authentification. Vos utilisateurs vous en seront reconnaissants.
Il y a deux parties d’Amazon Cognito qui valent la peine d’être comprises :
- Identity Pool : il stocke les identités de vos utilisateurs et les utilise pour fournir des jetons d’accès aux ressources au sein de l’application. Il prend en charge à la fois l’utilisation non authentifiée et authentifiée.
- User Pool : il s’agit d’un répertoire utilisateur pouvant éventuellement être utilisé à côté d’un pool d’identités pour fournir des fonctionnalités de nom d’utilisateur/mot de passe.
Une des caractéristiques qui peut être source de confusion est que les pools d’identités et les pools d’utilisateurs prennent en charge tous les deux l’authentification Facebook et Google. La principale différence est que le pool d’utilisateurs vous permet de récupérer les informations de profil de Facebook ou Google.
Si votre application nécessite un accès aux données de profil, elle peut l’obtenir directement auprès du fournisseur d’authentification – alors, utilisez un pool d’identités. Si le code backend a besoin d’accéder aux données du profil, utilisez un pool d’utilisateurs.
Un dernier conseil – mettez en œuvre le contrôle d’accès à la porte d’entrée de cloud. Pour la plupart des applications, ce sera AWS AppSync ou Amazon API Gateway. Les fonctions des esclaves doivent juste faire confiance à la porte d’entrée afin de réduire les dépenses de calcul.
Numéro 4 : Messagerie et Diffusion en temps réel

Vous avez besoin d’analyses dans votre application. Aucune application moderne est sans analyse ces jours-ci.
Dans le cloud AWS, les deux services les plus populaires sont Amazon Pinpoint ou Amazon Kinesis avec un package de stockage de données et d’analyse évolutif.
Amazon Pinpoint est un service centralisé pour le pipeline d’analyse – qui consiste généralement en un SDK dans l’application qui soumet les données, le récepteur et le stockage du flux d’événements. Il offre également la segmentation des utilisateurs et la gestion des campagnes pour fournir un service de participation des utilisateurs.
Amazon Kinesis n’est qu’une partie d’un pipeline d’analyse. Vous devrez fournir le SDK et relier Kinesis dans un entrepôt d’analyse comme Amazon Aurora.
Vous devrez également fournir vos propres rapports d’analyse tels que Amazon Quicksight. Vous utiliserez probablement cette option si vous souhaitez que vos données analytiques soient disponibles via SQL et qu’elles génèrent des applications telles que Tableau. Il en faut plus pour la mise en place, mais cela ne permet pas à l’utilisateur de participer à l’analyse.
L’engagement des utilisateurs est une partie importante du service backend de toute application moderne. Vous utiliserez des analyses pour diffuser des messages multicanaux à vos utilisateurs finaux en fonction de la démographie et de l’utilisation. Analytics gère également les tests A/B, l’étude du flux de comportements et l’identification des tendances pour les améliorations.
Numéro 5 : Soyez Global
Passer d’une seule région à plusieurs régions est un must pour toute application sérieuse. Des problèmes arrivent sans doute. Aucun fournisseur cloud n’est à l’abri de l’échec – et votre application hébergée dans une seule région va baisser à un moment donné.
Vous devez concevoir pour la résilience.

Pour le contenu statique, utilisez un CDN pour isoler vos utilisateurs de ces échecs. Un CDN a des centaines de points de transfert pour stocker les dernières données. Même les applications relativement petites peuvent bénéficier de l’utilisation d’un CDN – d’autant plus que c’est l’une des fonctionnalités qui est vraiment facile à configurer.
Pour le contenu dynamique, répliquez les données, puis déployez les APIs dans plusieurs régions. Pour DynamoDB, vous pouvez tirer parti des tables globales pour la disponibilité entre les régions.
Amazon Aurora a la capacité de produire des répliques. Utilisez ensuite Amazon Route53 pour accéder au service disponible le plus proche. Si un site tombe en panne, Route53 redirige automatiquement vers l’autre site – une fonctionnalité connue sous le nom de routage basé sur la latence.
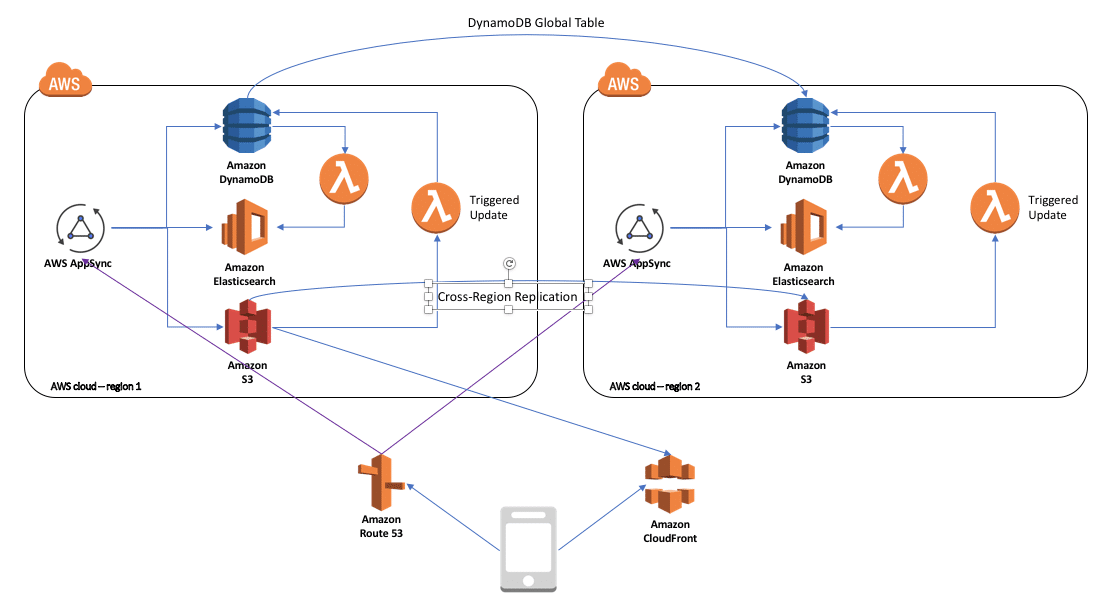
Notez que dans ce diagramme, l’application mobile recherche un enregistrement d’alias géré par la fonction de routage basée sur la latence Route 53, puis ouvre une connexion à l’instance AWS AppSync appropriée (la plus proche disponible). Il ne passera pas par le service Route 53.
Dans le cas d’une panne de région complète :
- Les clients déjà connectés verront leur connexion réinitialisée. L’application doit gérer les reconnexions silencieusement.
- Les clients qui se connectent lorsqu’une région est en panne ou indisponible seront acheminés vers la région la plus proche.
- Les téléchargements de fichiers proviennent d’une seule région. En cas d’échec, une intervention manuelle peut être nécessaire pour que les transferts de fichiers soient distribués à CloudFront.
Numéro 6 : Surveillance et déploiements des systèmes

Avez-vous confiance en votre propre code ? Non, si vous utilisez beaucoup de bibliothèques pour remplir certaines fonctions. Il y a un certain nombre de risques associés à ces bibliothèques. Pour cette raison, vous avez besoin d’une solide stratégie de surveillance et de journalisation.
Le backend nécessite plus que les analyses. La plate-forme d’analyse est utilisée pour enregistrer des informations pertinentes sur l’application dans son état naturel. En outre, la plupart des backend d’applications nécessitent trois services supplémentaires pour une surveillance et des déploiements complets du système :
- AWS CloudFormation automatise le processus de déploiement de votre service. Disons que vous ne voulez pas faire une multi-région, mais devez garder vos coûts bas. Vous devriez toujours faire la réplication de données afin que vous ayez une région de récupération après sinistre, puis utiliser un script AWS CloudFormation si la région principale tombe en panne. Le CFT peut être géré via le contrôle de la source et vérifié pour déployer un nouvel environnement de développement, de test ou d’aiguillage.
- AWS CloudWatch est un service de surveillance pour les ressources cloud. Il suit les mesures, recueille les fichiers journaux et vous permet d’alerter sur n’importe quoi en définissant des alarmes. Il s’agit probablement de votre service de référence pour la surveillance de vos services back-end globaux.
- Pendant que CloudWatch surveille les services, AWS CloudTrail les audite. Il enregistre toutes les modifications apportées à vos ressources. Ceci est essentiel pour le suivi et l’analyse de la sécurité. Il est très utile en tant que complément de CloudWatch lorsque vous effectuez un dépannage des problèmes opérationnels, car vous pouvez identifier les changements de configuration dans les ressources.
Soyez prêt pour le succès !
La conception de votre application avec des services d’architecture et de backend sans serveur présente des avantages significatifs. Une approche bien architecturée permet à vos composants backend d’évoluer indépendamment tout en étant résilient aux pannes, tout en réduisant vos coûts et en rendant vos clients plus heureux.
Le succès arrive. Assurez-vous que vous êtes prêt pour le recevoir !




