

Mis à jours 16 avril 2018 Une liste d’outils, de conseils et d’astuces sans serveur (Serverless) que vous devriez savoir
On a beaucoup appris en déployant une application sans serveur – y compris quelques outils et astuces qui auraient pu nous faire économiser de l’énergie gaspillée. Voici la liste des solutions sans serveur et des conseils qui vous aideront à se détacher des instances et de rester sans serveur.
Numéro 1 : The Serverless Framework

Il y a trois choses qui deviennent souvent confuses quand on parle de sans serveur. Avant de commencer, faisons une distinction claire :
La méthodologie
L’architecture sans serveur est une méthodologie agnostique pour les fournisseurs. Cela ne signifie pas qu’il n’y a pas de serveurs impliqués. Cela signifie simplement que vous ne gérez pas les serveurs – c’est la responsabilité du fournisseur dans le cadre du service.
L’outil
The Serverless Framework est un outil de ligne de commande multi-fournisseurs qui automatise et élimine une tonne de tâches manuelles autrement nécessaires pour développer, tester et gérer de nombreux services derrière une pile sans serveur.
L’entreprise
Serverless Inc. est le nom de la société qui développe et maintient The Serverless Framework. Austen Collins, fondateur et PDG, a été le créateur original du Serverless Framework.
Au moment de la rédaction de cet article, Serverless Framework prend en charge 4 fournisseurs de cloud majeurs : Amazon Web Services, Google Cloud Platform, Microsoft Azure et IBM OpenWhisk.

Le framework fonctionne en créant un fichier serverless.yml relativement simple qui définit vos fonctions, vos événements et vos ressources. Le Serverless Framework (SLS) va ensuite déployer et provisionner tout avec une simple commande de déploiement sls (sls deploy). Vous pouvez également faire des choses comme engendrer des logs de Lambda CloudWatch avec sls logs –f functionName directement dans votre terminal.
Exemple de Serverless Framework YAML :
service: service-name
provider:
name: aws
runtime: nodejs6.10
region: us-east-1
functions:
hello:
handler: handler.hello
events:
- http:
path: users/create
method: get
resources:
Resources:
NewResource:
Type: AWS::S3::Bucket
Properties:
BucketName: my-new-bucket
Outputs:
NewOutput:
Description: "Description for the output"
Value: "Some output value"
Lorsque vous utilisez AWS en tant que fournisseur, SLS convertit votre YAML en un modèle AWS CloudFormation (CFN), le télécharge dans un ensemble de déploiement créé automatiquement, puis déclenche la création de la pile CFN.
Jusqu’à présent, travailler avec SLS a été incroyable. Même s’il est encore relativement nouveau, le framework est rapidement devenu notre outil de facto pour créer, déployer et tester nos applications sans serveur.
Le framework est vraiment le catalyseur qui nous fait dépendant du sans serveur. Pour vous aider à démarrer, consultez certains de leurs exemples sur GitHub.
Numéro 2 : Utilisez des variables SSM et d’environnement
Simple Systems Manager (SSM) est un excellent magasin centralisé de configuration de cloud qui peut être utilisé sur plusieurs piles. Il peut également résoudre quelques problèmes courants de la CFN, tels que les dépendances cycliques et les limites de temps de déploiement.
- Pour commencer, créez une ressource SSM et définissez-la comme une valeur :
---
Type: "AWS::SSM::Parameter"
Properties:
Name: awesomeParam
Description: A Great Param
Type: String
Value: {Ref: SomeResourceID}
- Ensuite, utilisez ce paramètre dans vos fonctions lambda
const AWS = require('aws-sdk');
const ssm = new AWS.SSM({ apiVersion: '2014-11-06' });
exports.handler = (event, context, cb) => {
ssm
.getParameter({ Name: 'awesomeParam' })
.promise()
.then(resp => {
const value = resp.Parameter.Value;
cb(null, `Success: the param value is ${value}`);
})
.catch(err => {
cb(err, 'Error');
});
};
SSM est assez simple – et un moyen très puissant de gérer les variables. Pour ce qu’il vaut, vous pouvez également utiliser le Serverless Framework pour lire et créer des paramètres SSM.
Il est important de noter que SSM ne doit pas être utilisé à la place des env vars (variables d’environnement) – elles sont utilisées pour résoudre différents problèmes. Les variables d’environnement sont encore meilleures lorsque vous savez comment les utiliser au moment du déploiement – et lorsque les valeurs n’ont pas besoin d’être cryptées. Les variables d’environnement sont également quasi instantanées pour accéder dans vos fonctions lambda.
SSM est un meilleur choix lorsque vous ne connaissez pas une valeur au moment du déploiement – ou s’il existe des problèmes de dépendance cyclique. Vous pouvez également chiffrer les valeurs SSM à l’aide de KMS. L’inconvénient de SSM est qu’il nécessite un appel au service. Bien que ce soit généralement très rapide, cela pourrait faire la différence dans votre scénario.
Numéro 3 : Utilisez Lambda@Edge pour configurer les applications monopage (Single Page Apps ou SPA)

Les statuts HTTP appropriés et les jolies URL sont définitivement des choses faciles à tenir pour acquises. Quand une page existe, elle devrait retourner un statut « 200 OK ». Lorsque la page ou un élément est manquant, il doit retourner un statut « 404 ».
En outre, les URLs doivent ressembler à ceci : https://www.domain.com/paths/, et non ceci : https://www.domain.com/paths/index.html. Les URLs ne doivent pas non plus avoir besoin de 30 redirections.
Là, les choses peuvent traditionnellement être accomplies sur un serveur web/proxy (httpd, nginx) avec un fichier .htaccess. C’est simple – n’est-ce pas ?
Malheureusement, Static Website Hosting d’Amazon S3 ne prend actuellement en charge qu’une partie de ces fonctionnalités, seulement celles qui sont vraiment nécessaires pour la production. La raison principale en est la façon dont S3 gère votre fichier index.html.
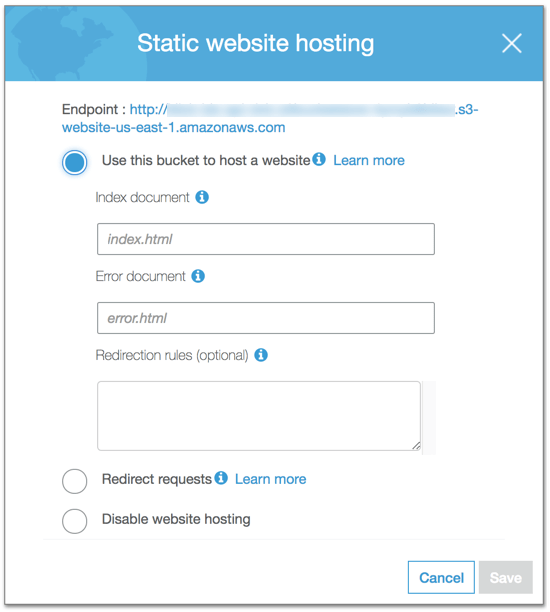
De nombreux articles sur les applications monopage (SPA) proposent de définir à la fois le document d’Index et le document d’erreur sur votre index.html.
Le document d’Index et le document d’erreur dictent quel fichier servir lorsqu’une requête est adressée à un répertoire /path par rapport à un fichier /path/file.html, et que faire si une requête demande un fichier qui n’existe pas.
Dans le cas d’une demande adressée à https://www.domain.com/somePath/, votre site sera téléchargé pour l’utilisateur final comme prévu. Toutefois, si vous inspectez le panneau réseau, la réponse renvoyée par le serveur est un 404 introuvable.
C’est parce que le dossier /somePath/ n’a pas été trouvé dans S3, donc il a servi votre index.html choisi comme document d’erreur – qui à son tour gère l’itinéraire et fournit la bonne page à l’utilisateur.
Il y a un certain nombre de raisons pour lesquelles toutes les routes non-root de votre site répondent comme 404. Les moins importantes sont les dégradations du référencement SEO, SEM considérant que votre site est en panne et supprimant ainsi les annonces, et c’est une mauvaise expérience utilisateur.
Cependant, est-il juste de dire que c’est tout simplement déplaisant ?
Utiliser Lamdba@Edge
L’utilisation de Lambda@Edge vous permet d’associer une fonction Lambda personnalisée à chaque requête entrant dans CloudFront (CF). Dans le code de la fonction, vous apportez toutes les modifications que vous souhaitez à la requête – c’est pareil à ce que vous pourriez faire dans un fichier .htaccess.
Réécriture d’URL Lambda@Edge :
const path = require('path');
const { STATUS_CODES } = require('http');
exports.rewriteHandler = (evt, ctx, cb) => {
const { request } = evt.Records[0].cf;
const htmlExtRegex = /(.*)\.html?$/;
if (htmlExtRegex.test(request.uri)) {
const uri = request.uri.replace(htmlExtRegex, '$1');
return cb(null, redirect(uri));
}
if (!path.extname(request.uri)) {
request.uri = '/index.html';
}
cb(null, request);
};
function redirect(to) {
return {
status: '301',
statusDescription: STATUS_CODES['301'],
headers: {
location: [{ key: 'Location', value: to }],
},
};
}
Maintenant, lorsqu’une requête est adressée à https://www.domain.com/somePath/, le Lambda vérifie d’abord si le chemin est dans un répertoire ou un fichier HTML – et si c’est le cas, il réécrit cette requête pour pointer vers votre fichier index.html. Sinon, si la requête concerne un actif, elle reste inchangée sur S3, et réussit ou échoue selon l’existence ou non de l’actif.
Cela fonctionne également pour les routes insensibles à la casse telles que domain.com/MyPath/ -> domain.com/mypath/ et les réécritures canoniques domain.com -> www.domain.com. Pour la solution canonique, l’hébergement standard de sites Web statiques S3 vous demande de configurer deux distributions CloudFront soutenues par un compartiment qui vous redirige vers le compartiment www actuel. Si cela semble un peu compliqué, vous n’êtes probablement pas seul.
Avec Lambda@Edge, vous pouvez simplement réécrire les requêtes en face de votre application comme vous le feriez normalement, mais sans avoir besoin d’un serveur Web ou d’une instance de proxy.
Lorsque vous utilisez CloudFront et S3, vous pouvez également limiter le trafic au compartiment à celui provenant du CF CDN. Cela empêche le trafic d’accéder directement au compartiment, ce qui peut avoir un impact sur les coûts. AWS ne double pas avec le trafic de CDN, donc c’est gratuit sur le côté S3.

Numéro 4 : Comment supprimer les fonctions Lambda@Edge ?

Avant le JAN-26-2018, vous ne pouviez pas supprimer une fonction Lambda@Edge de quelque manière que ce soit. Oui. C’est exact – une fois créée, vous n’aviez aucun moyen de la supprimer.
Supprimer la ressource de votre modèle CloudFormation entraînerait simplement une erreur dans votre pile. Essayer de les supprimer manuellement serait également une erreur. Ce n’est pas que cela vous coûte quelque chose d’avoir des Lambda inutilisés, mais cela devient vite désordonné dans la console.
Certains développeurs pensaient que c’était bizarre – AWS a rapidement trouvé un moyen de nous permettre de les supprimer manuellement. Voici comment faire :
- Dissociez la ressource de toutes les distributions CloudFront: les fonctions Lambda@Edge précédemment dissociées (avant 1/26) ne pourront pas encore être supprimées. Cela prend environ 30 minutes pour que le système nettoie des choses telles que vos fonctions de réplique.
- Supprimez-les manuellement : une fois les fonctions de réplique nettoyées, vous pouvez le supprimer manuellement. Lambda@Edge semble avoir créé de tels problèmes pour quelque chose comme suppressions, mais il semble que la résolution complète de ce problème soit l’une des priorités d’AWS. On espère juste qu’ils fournissent un moyen d’autoriser les piles CloudFormation à supprimer sans erreur ou blocage en cas de déchirement. Pour le moment cependant – on le supprime manuellement.
Numéro 5 : Utilisez WAF pour mettre votre site sans serveur dans la liste blanche/noire
Comme il n’y a pas de serveur web/proxy typique, il n’est pas possible de faire fonctionner des sites de développement avec une simple authentification de base. Toutefois, avec AWS WAF, vous pouvez configurer toutes sortes de règles pour bloquer le trafic.
Voici un très petit exemple de la puissance de WAF – il est fortement recommandé d’explorer ce service pour votre propre site.
Exemple de configuration WAF pour la liste blanche avec accès à une adresse IP unique
Resources:
WebACL:
Type: "AWS::WAF::WebACL"
Properties:
DefaultAction:
Type: BLOCK
MetricName: "TrustedIPs"
Name: "TrustedIPs"
Rules:
- Action:
Type: ALLOW
Priority: 1
RuleId: {Ref: WAFRule}
WAFRule:
Type: "AWS::WAF::Rule"
Properties:
Name: "MyIPSetRule"
MetricName: "MyIPSetRule"
Predicates:
- DataId: {Ref: WAFIpSet}
Negated: false
Type: "IPMatch"
WAFIpSet:
Type: "AWS::WAF::IPSet"
Properties:
IPSetDescriptors:
- Type: "IPV4"
Value: "192.168.1.1/32" # Your whitelist IP Here
Name: IPSet for whitelisted IP adresses
Numéro 6 : Créez vos propres ressources CloudFormation
Ce ne sont pas tous les services AWS qui sont pris en charge dans CloudFormation – et certains ne le sont que partiellement. Vous pouvez également souhaiter que certains services en dehors d’AWS puissent être utilisés dans les modèles CloudFormation. Eh bien, ces deux scénarios peuvent être résolus avec CloudFormation Custom Resources.
Custom Resources ne sont vraiment pas beaucoup plus qu’une fonction Lambda qui agit au nom de vos modèles CloudFormation pour créer, mettre à jour et supprimer un type spécifique de ressource que vous définissez. Cette fonction Lambda est indépendante des déploiements qui sont susceptibles de l’utiliser.
Pour un exemple, prenez AWS Elastic Transcoder. Il n’existe actuellement aucun service CloudFormation officiel pris en charge pour les ressources nécessaires pour Pipeline et Preset. Cependant, avec un peu plus de 40 lignes de code et l’aide de AWS JS SDK, vous pouvez le créer et le personnaliser.
var AWS = require('aws-sdk');
var elastictranscoder = new AWS.ElasticTranscoder();
var Create = function(params, reply) {
elastictranscoder.createPipeline(params, function(err, data) {
if (err) {
console.error(err);
reply(err);
} else {
reply(null, data.Pipeline.Id, { "Arn": data.Pipeline.Arn });
}
});
};
var Update = function(physicalId, params, oldParams, reply) {
params.Id = physicalId;
delete params.OutputBucket;
elastictranscoder.updatePipeline(params, function(err, data) {
if (err) {
console.error(err);
reply(err);
} else {
reply(null, data.Pipeline.Id, { "Arn": data.Pipeline.Arn });
}
});
};
var Delete = function(physicalId, params, reply) {
var p = {
Id: physicalId
};
elastictranscoder.deletePipeline(p, function(err, data) {
if (err) console.error(err)
reply(err, physicalId);
});
};
exports.Create = Create;
exports.Update = Update;
exports.Delete = Delete;
Il y a aussi un excellent service Custom Resource appelé cfn-lambda, qui aide avec un grand nombre de tâches standard.
En prenant ce même concept – imaginez maintenant que vous créez une ressource personnalisée pour les services tiers comme Auth0. Même avec des services en dehors d’AWS, vous pouvez désormais orchestrer l’ensemble de votre pile depuis CloudFormation. C’est vraiment surprenant.
Bon déploiement !
Voilà, c’est juste quelques petites choses qu’on doit apprendre tout en déployant des solutions sans serveur. Cela vous fera économiser du temps et de l’énergie !
Merci d’avoir pris le temps de lire cet article. Ce serait très intéressant de lire vos commentaires, suggestions et expériences ci-dessous !




